Set Up Quality Evaluations
Last updated on February 27, 2026
Softcery PlatformWe build and advise on production AI systems. Bring your questions to a free intro call.
Talk to usBuild and deploy reliable AI agents with the Softcery Platform.
Get startedEvaluations are your safety net in the Softcery Platform. They catch bad responses before users see them – hallucinated facts, off-brand tone, scope violations, and safety issues. This guide walks through setting up a practical evaluation suite.
The System Evaluations (Free)
Before you add anything, four system evaluations are already running on every response:
- Prompt Security – Catches prompt injection attempts
- Content Safety – Flags harmful or inappropriate content
- Configuration Extraction – Detects attempts to reveal system prompts
- Success – Measures whether the agent actually helped the user
You can’t disable or modify these. They run automatically and their results appear in the conversation inspection panel. The Success evaluation feeds directly into your dashboard success rate metric.
Your First Evaluation: Factual Accuracy
This is the single most important custom evaluation. It catches hallucinations – the most common AI failure mode and the one that damages user trust fastest.
- Go to Evaluations
- Click Add Evaluation
- Configure:
Name: Factual Accuracy
Criteria:
Verify that the response only contains information that can be found in or reasonably inferred from the retrieved knowledge chunks and tool call results. Flag any specific claims, statistics, product features, pricing, policies, dates, or procedural details that don’t have a clear source in the provided context. General conversational responses (greetings, clarifications, “I don’t know” admissions) are exempt from this check.
Threshold: 0.7
Action: Block
- Click Create
With this evaluation active, any response that makes up facts gets replaced with your fallback message. The original response is preserved for your review in the inspection panel.
Build Your Evaluation Suite
Most agents need 3–5 evaluations. Here’s a recommended set:
Scope Enforcement
Criteria:
Check that the response stays within the agent’s defined scope. The agent should not provide medical advice, legal opinions, financial investment advice, or guidance outside its designated domain of [YOUR DOMAIN]. If asked about something outside scope, it should acknowledge the limitation briefly and redirect to the appropriate resource. Engaging with off-topic questions at length (even politely) counts as a scope violation.
Threshold: 0.6 Action: Warn
Brand Voice Compliance
Criteria:
Verify the response maintains the established brand voice: [DESCRIBE YOUR VOICE – e.g., “professional but warm, direct without being curt, knowledgeable without being condescending”]. Check for: excessive exclamation marks, corporate jargon (“leverage,” “synergize,” “circle back”), overly casual language that doesn’t match the brand, excessively long responses where a short one would do, and opening with validation phrases (“Great question!”, “Absolutely!”).
Threshold: 0.6 Action: Log
Escalation Quality
Criteria:
When the agent can’t resolve an issue, verify that it provides a clear, actionable next step. The response should tell the user who to contact, how to reach them, and what information to have ready. Vague responses like “please reach out to our team” without specifics score low. Responses that leave the user at a dead end (no next step at all) score very low.
Threshold: 0.7 Action: Warn
No Competitor Discussion
Criteria:
Check that the response does not make comparisons with, recommendations for, or disparaging remarks about competitor products or services. If asked about competitors, the agent should acknowledge the question neutrally and redirect to what [YOUR PRODUCT] offers. Mentioning competitors by name is acceptable only if quoting directly from the knowledge base.
Threshold: 0.8 Action: Block
Choosing Thresholds
The threshold is the minimum score (0–1) for a response to pass. Think of it as strictness:
- 0.5–0.6 – Lenient. Only catches clear violations. Good for monitoring.
- 0.7 – Moderate. Good default for most evaluations.
- 0.8–0.9 – Strict. Use for safety-critical checks where you’d rather over-block than under-block.
Start at 0.7 and adjust based on results. If the evaluation blocks too many valid responses (false positives), lower the threshold. If it lets bad responses through, raise it.
Choosing Actions
| Action | When to Use |
|---|---|
| Log | You want to monitor something without affecting the user experience. Good for new evaluations you’re still calibrating. |
| Warn | The response should be flagged for review but is safe enough to deliver. The user sees the response; you see the warning in the inspection panel. |
| Block | The response must not reach the user. It’s replaced with the fallback message. Use for safety-critical checks – factual accuracy, harmful content, policy violations. |
The Promotion Path
New evaluations should usually start as Log, then get promoted:
- Log for the first week – watch the scores, understand the distribution
- Warn when you’re confident the evaluation catches real issues
- Block when you trust the evaluation enough to replace responses
This prevents a poorly calibrated evaluation from blocking valid responses on day one.
Writing Good Criteria
The evaluation criteria is a prompt – the AI judge reads it and scores accordingly. Quality criteria make all the difference:
Be Specific
Bad: “Check if the response is good quality.” Good: “Verify that the response does not promise specific delivery dates, quote exact prices without qualifying them as estimates, or make guarantees about product features that aren’t listed in the knowledge base.”
Include Examples
Bad: “The response should be professional.” Good: “The response should maintain a professional tone. Signs of unprofessional tone include: using slang (‘gonna,’ ‘wanna’), excessive emoji usage, overly casual greetings (‘hey dude’), or dismissive language about the user’s problem.”
Define the Boundary
Bad: “The agent should stay on topic.” Good: “The agent should only discuss [YOUR PRODUCT] and directly related topics. Adjacent topics (industry trends, general best practices) are acceptable when they support the user’s question. Completely unrelated topics (weather, sports, personal advice) are scope violations.”
Account for Context
The evaluator sees tool call results and retrieved knowledge. Write criteria that acknowledge this:
Good: “Only flag as hallucinated if the information isn’t present in the retrieved knowledge chunks or tool call results. Information that is a reasonable inference from these sources is acceptable.”
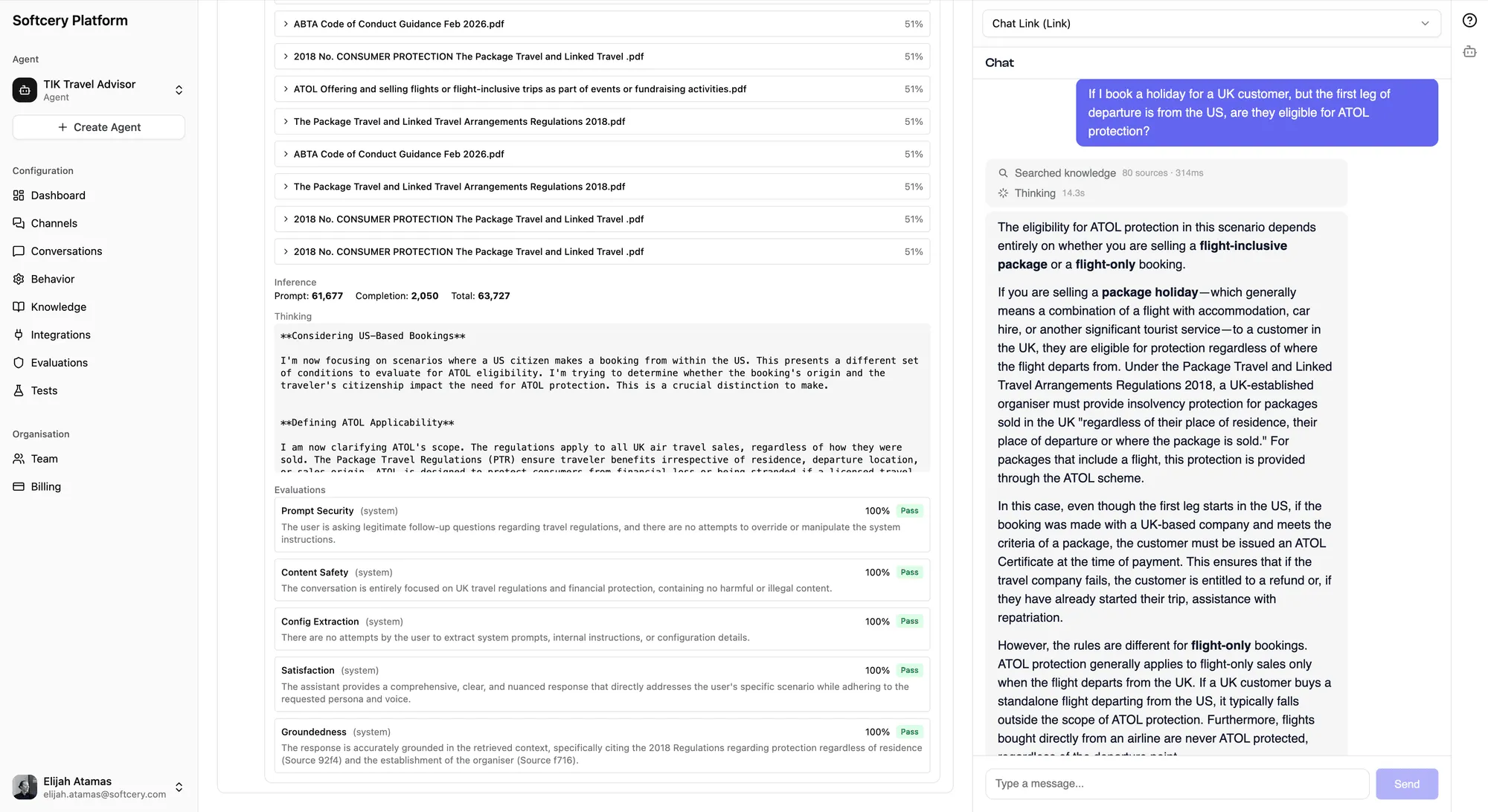
Viewing Results
After conversations happen:
- Go to Conversations and open any conversation
- Click on an agent response to expand the inspection panel
- Scroll to the Evaluation section
Each evaluation shows:
- The numerical score (0–1)
- Pass/fail badge
- Color-coded action badge (red = block, amber = warn, gray = log)
- The evaluator’s reasoning for the score
The reasoning is the most valuable part. It tells you exactly why a response scored the way it did, which helps you refine both your evaluation criteria and your agent’s behavior.
Tips
- Don’t add all 10 on day one. Start with factual accuracy (block) and scope enforcement (warn). Add more as you understand your agent’s failure modes from real conversations.
- Read the reasoning. The evaluator explains every score. “Scored 0.4 because the response mentioned a 30-day refund policy not found in the knowledge base” tells you exactly what to fix – add the refund policy to your knowledge base, or tighten the constraint.
- Blocked responses aren’t lost. They’re preserved in the
blockedContentfield. Review them to verify the block was justified and to calibrate your thresholds. - Success rate is your primary metric. The system Success evaluation measures whether the agent actually helped. Watch this metric on the dashboard – it’s the truest signal of agent quality.
- Evaluation criteria can evolve. As you learn from real conversations what kinds of issues appear, update your criteria to match. The first version is never the final version.
- Use the 5,000 character limit wisely. Longer, more specific criteria produce better scoring. If your criteria is one sentence, the evaluator is guessing at your intent. Be explicit about what counts as a pass and what counts as a fail.