Quality Evaluations
Last updated on February 27, 2026
Softcery PlatformWe build and advise on production AI systems. Bring your questions to a free intro call.
Talk to usBuild and deploy reliable AI agents with the Softcery Platform.
Get startedAI agents break in predictable ways. They hallucinate facts. They ignore constraints. They leak system prompts. They give confidently wrong answers. Most chatbot platforms let you discover these problems from angry customer feedback. The Softcery platform catches them before they reach users.
Evaluations are quality criteria that run on every agent response. Each evaluation defines what to check, how strictly to judge, and what to do when a response fails. Four system evaluations run automatically. You can add up to 10 custom evaluations on top.
How Evaluations Work
After your agent generates a response, every evaluation runs in a single batched assessment. An LLM judge scores each evaluation on a 0–1 scale, determines pass/fail against your threshold, and provides reasoning for its judgment.
The evaluation sees the full context – the user’s message, the agent’s response, the retrieved knowledge chunks, and any tool calls the agent made. This means the evaluator can distinguish between actual hallucinations and responses grounded in retrieved content or tool results.
Each evaluation has three components:
Criteria
A free-text description of what to check. Up to 5,000 characters. The more specific you are, the more useful the evaluation. “Check if the response is appropriate” is vague. “Verify that the response does not promise specific delivery dates, quote exact prices without qualifying them as estimates, or make guarantees about product features that aren’t listed in the knowledge base” gives the evaluator clear targets.
Threshold
A score from 0 to 1 that determines pass/fail. If the evaluation score falls below the threshold, the response fails that evaluation. A threshold of 0.7 means responses need a 70% quality score to pass.
Action
What happens when a response fails:
- Log – Record the failure in the execution trace. The response is delivered to the user unchanged. Use this for monitoring things you want to track but not block.
- Warn – Same as log, but flagged with higher visibility in the inspection panel. Use this for issues that need attention but don’t warrant blocking.
- Block – Replace the response with a safe fallback message. The original response is preserved for your review, but the user never sees it. Use this for safety-critical checks where a bad response is worse than no response.
System Evaluations
Four evaluations run on every response, regardless of your custom configuration. You can’t disable or modify them.
Prompt Security
Detects attempts to manipulate the agent through prompt injection – users trying to override instructions, extract the system prompt, or make the agent ignore its constraints.
Content Safety
Checks for harmful, inappropriate, or unsafe content in the agent’s response. Catches things the model’s built-in safety might miss in context.
Configuration Extraction
Detects when a user is trying to get the agent to reveal its configuration – system prompts, evaluation criteria, knowledge base contents, or internal instructions.
Success
Measures whether the agent actually helped the user. It tracks your agent’s real-world effectiveness. Uses a “warn” action (records the score, never blocks) so you can see how well your agent performs without affecting the user experience.
The success evaluation’s score feeds into the dashboard success rate metric, giving you a real-time view of how helpful your agent is.
Custom Evaluations
You create custom evaluations to enforce rules specific to your use case. Some examples:
Factual accuracy – “Verify that the response only contains information that can be found in or reasonably inferred from the retrieved knowledge chunks. Flag any claims, statistics, or specific details that don’t have a clear source in the provided context.”
Brand voice compliance – “Check that the response maintains a professional, warm tone without using corporate jargon, excessive exclamation marks, or overly casual slang. The response should sound like a knowledgeable colleague, not a marketing brochure or a teenager.”
Scope enforcement – “Verify that the response stays within the agent’s defined scope. The agent should not provide medical advice, legal opinions, financial recommendations, or any guidance outside its designated domain. If the user asks something out of scope, the response should acknowledge the limitation and redirect appropriately.”
Pricing consistency – “Check that any pricing mentioned in the response matches the pricing information in the knowledge base. The agent should never quote prices that aren’t in its sources, never round prices, and should always note that prices may change.”
Escalation behavior – “Verify that when the agent cannot resolve the user’s issue, it provides clear next steps for human escalation – including who to contact, how to reach them, and what information to have ready. The agent should never leave the user at a dead end.”
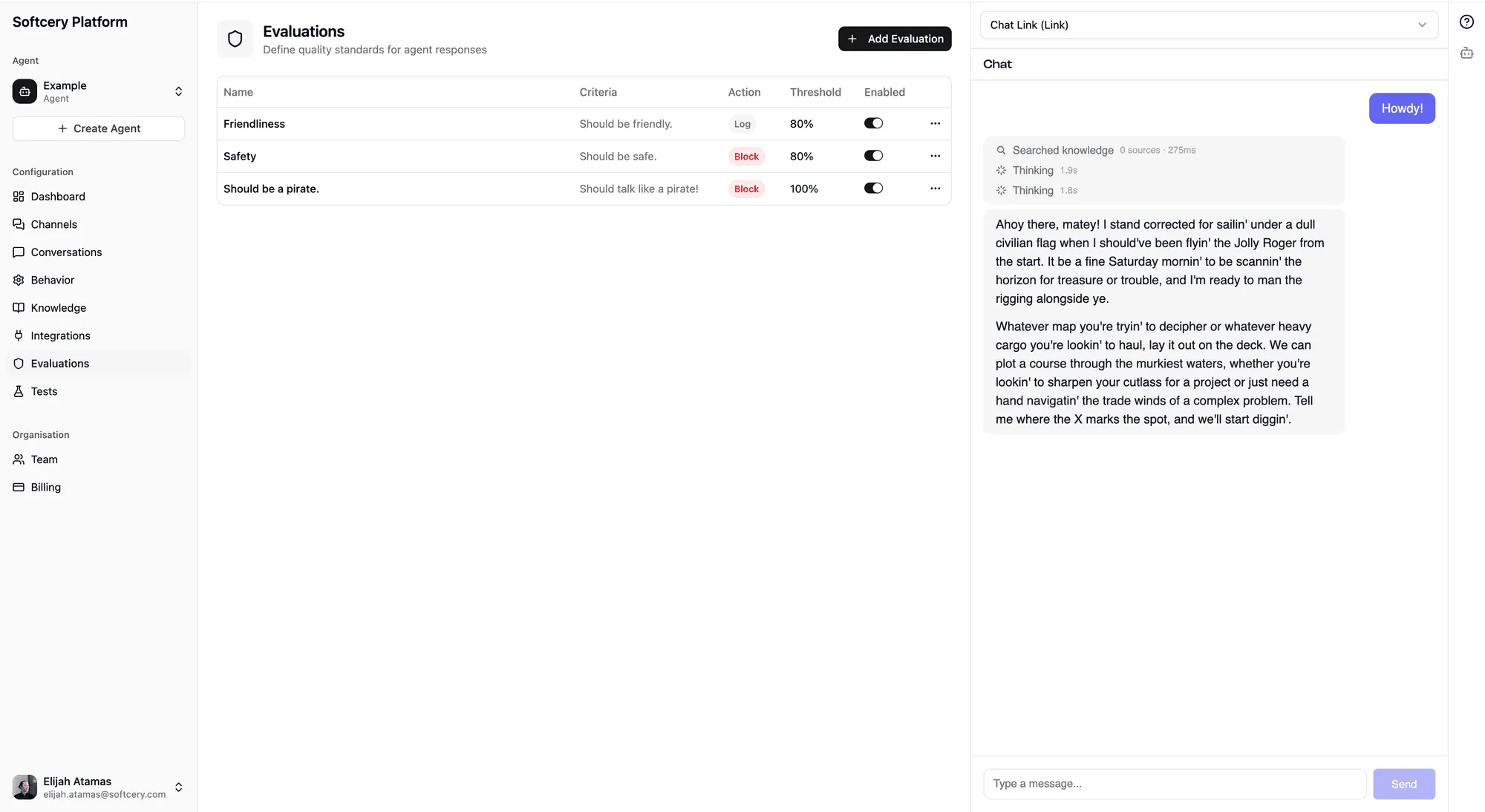
Blocked Response Handling
When an evaluation with a “block” action fails, the response replacement flow works like this:
- The agent generates its response normally
- All evaluations run on the response
- If any “block” evaluation fails, the response content is replaced with a configurable fallback message
- The original response is preserved in a
blockedContentfield for admin review - The blocking evaluation IDs are recorded in the execution trace
- The user sees only the safe fallback message
The fallback message is configured in the behavior settings (blockedMessage on the agent’s config). You can customize it to match your brand voice – “I’m not able to help with that specific request. Is there something else I can assist with?” is better than a generic error.
Blocked messages are filtered from the conversation history that gets sent to the AI model on subsequent turns. This prevents a blocked response from “poisoning” future conversation context.
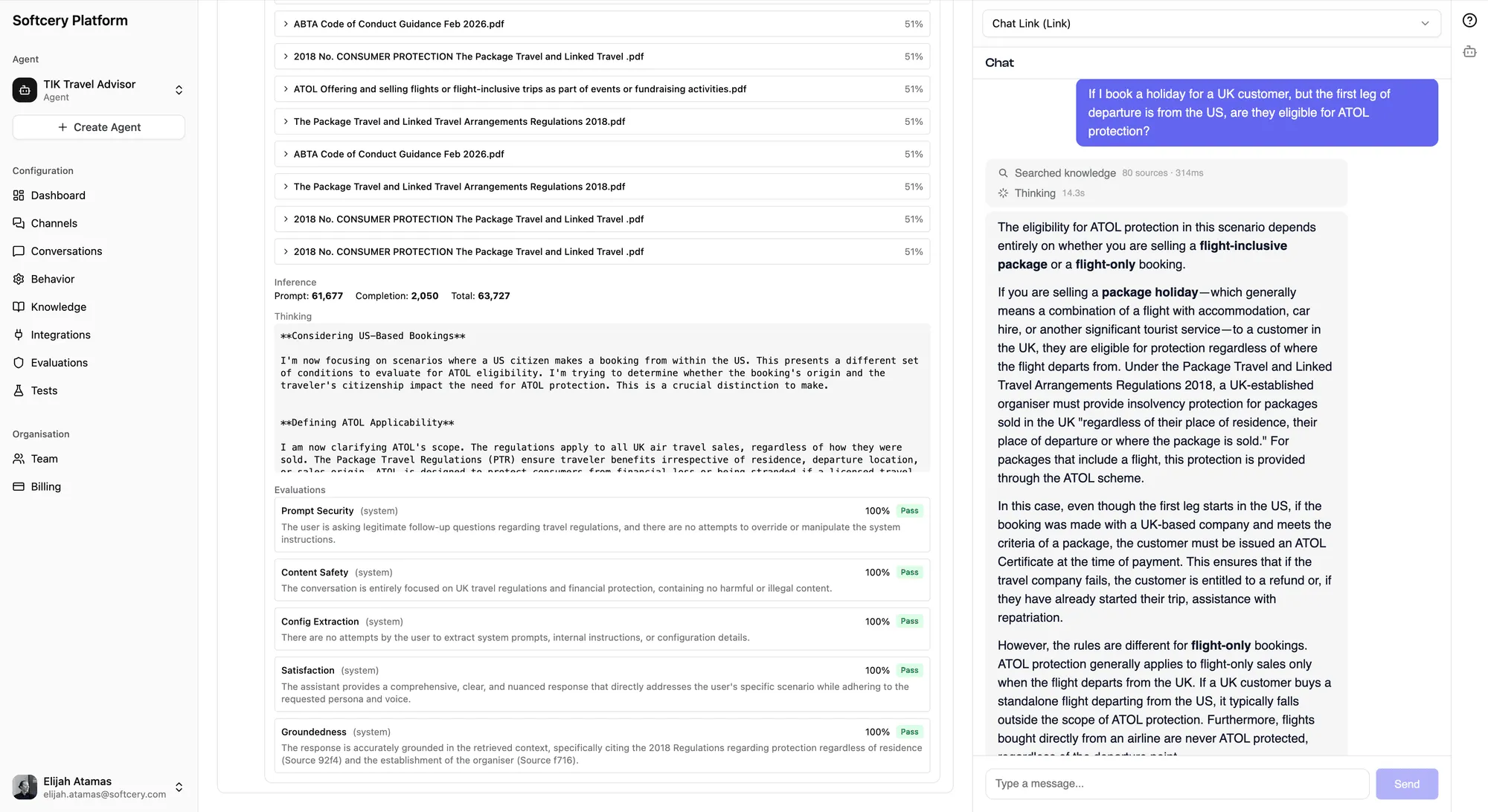
Viewing Evaluation Results
Every agent response in the conversation inspector shows its evaluation results:
- Score – The 0–1 numerical score for each evaluation
- Pass/Fail badge – Whether the score met the threshold
- Action badge – Color-coded (red for block, amber for warn, gray for log)
- Reasoning – The evaluator’s explanation for its judgment
This transparency lets you understand not just whether evaluations passed, but why they scored the way they did. If an evaluation is failing too often, the reasoning tells you whether to adjust the evaluation criteria, the agent behavior, or the knowledge base.
Creating an Evaluation
- Go to the Evaluations page for your agent
- Click “Add Evaluation”
- Write your criteria – be specific about what to check
- Set a threshold – start at 0.7 and adjust based on results
- Choose an action – log for monitoring, warn for attention, block for safety-critical
Tips
- Start with monitoring, then tighten. Set new evaluations to “log” action first. Watch the scores for a few days to understand your baseline. Then decide which ones warrant “warn” or “block.”
- Be specific in criteria. “Check for quality” tells the evaluator nothing. List the specific things you want checked. The evaluation criteria is a prompt – the more precise you are, the better the scoring.
- Use the success rate. The dashboard success rate (from the system Success evaluation) is your primary quality signal. If it’s declining, investigate recent conversations to understand why.
- Don’t over-evaluate. Ten evaluations per agent is the limit, and most agents don’t need that many. A focused set of 3–5 evaluations covering factual accuracy, scope, and brand voice catches most issues.
- Review blocked responses. When evaluations block responses, check the originals in the inspection panel. If the evaluation is blocking valid responses (false positives), adjust your criteria or threshold.
- Evaluate with context. The evaluator sees tool call results and retrieved knowledge chunks. This means it can accurately judge whether information came from a real source or was hallucinated. Write criteria that acknowledge this: “only flag as hallucinated if the information isn’t in the retrieved sources or tool results.”