9 AI Observability Platforms Compared: Phoenix, Langfuse, Logfire, & More
Last updated on April 28, 2026
We build and advise on production AI systems. Bring your questions to a free intro call.
Talk to usYou can not debug AI behavior by reading logs or running unit tests. A model might respond flawlessly one day and produce irrelevant, biased, or costly outputs the next.
AI observability platforms track everything from prompt performance and latency to reasoning paths, token usage, and hallucination rates. The right tool can mean the difference between scaling confidently and firefighting mysterious failures after launch.
Softcery is here to help you out and break down the top observability and evaluation platforms for AI agents in 2026: everything from open-source frameworks to enterprise-ready solutions. You’ll learn which tools fit an MVP budget, which integrate seamlessly into existing monitoring stacks, and which are worth investing in as your product matures.
The AI Agent Observability Platform Landscape
Not all AI observability tools are built the same. Depending on your stage, budget, and technical capacity, the right choice will look very different. All platforms fall into three main categories:
Open Source / Self-Hosted
Phoenix, Langfuse, Lunary, OpenLIT, Traceloop
Tools are free to use, but you host and manage them yourself (on your own servers, cloud instances, or containers.)
- Best for: Technical teams comfortable managing infrastructure, founders minimizing recurring costs, or companies with strict data sovereignty needs.
- Tradeoffs: You’re responsible for setup, scaling, and reliability. Getting started takes longer than plugging into a SaaS dashboard.
- Typical cost: USD 0 for software, plus around USD 50–2,000/month for infrastructure depending on scale.
Commercial SaaS (Fully Managed)
LangSmith, Helicone (maintenance mode), Braintrust, AgentOps, Datadog, Langfuse (Cloud), Pydantic Logfire
These platforms handle everything for you: infrastructure, scaling, and updates. You simply connect via API and start tracking.
- Best for: MVP or post-MVP teams that want fast results without heavy DevOps work. You get dashboards, alerts, and support out of the box, which helps move faster during early growth.
- Tradeoffs: You’ll pay recurring fees that grow with usage and have less control over your data and integrations.
- Typical cost: Free tiers available, with startup plans around USD 25–500/month, and enterprise plans reaching USD 2,000–10,000+ per month.
Hybrid / Enterprise Solutions
HoneyHive, Arize AX, Maxim AI
These are the heavyweights of AI observability, offering multiple deployment options: cloud, hybrid, or fully on-premises.
- Best for: Large organisations, compliance-driven industries, or teams scaling mission-critical AI systems.
- Tradeoffs: Higher cost, longer onboarding, and often overkill for smaller startups.
- Typical cost: Custom pricing, typically USD 4,000–8,000/month minimum, or USD 50k–100k+/year.
Observability Tools’ Integration Approaches
The way you connect an observability tool to your AI agent can completely shape your development journey. Each integration approach balances setup speed, control, and data depth, so understanding which one is best for you is essential.
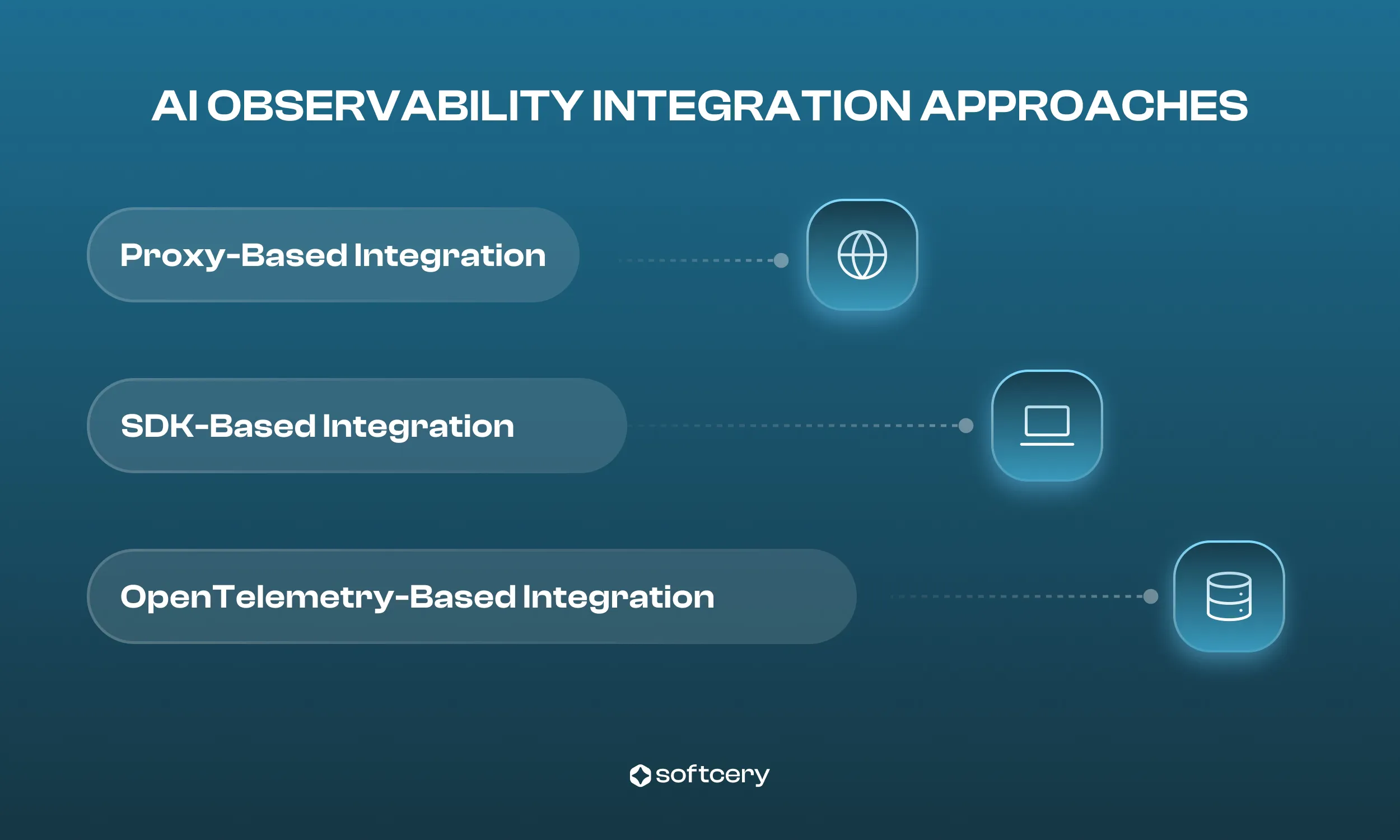
Proxy-Based Integration
You route your LLM requests through a gateway rather than directly to the API provider.
For example, you change your API endpoint from api.openai.com to oai.helicone.ai. The proxy logs every request and response before forwarding them to the real model.
Why it matters: This is the fastest and easiest way to start monitoring your AI agent. You don’t need to change your code logic, just your API URL.
Setup time: Around 15 minutes, typically one line of code.
Tradeoffs: Adds a small latency overhead (50–80 ms) and provides less granular data compared to SDK-based tools. The proxy also becomes a single dependency for all your LLM traffic.
Best for: Teams that want quick visibility into cost and performance without major code changes.
SDK-Based Integration
This method uses an SDK (software development kit) that you install directly in your application. The SDK instruments your agent’s logic, capturing detailed traces and sends them to the observability platform.
Why it matters: You get deep insights into your AI agent’s internal behavior, which will help you debug reasoning issues, monitor complex workflows, and measure model performance more accurately.
Setup time: Several hours to a few days, depending on your codebase complexity.
Tradeoffs: Requires more setup and code changes but provides richer analytics and tighter integration with your development workflow.
Best for: Teams ready to invest engineering time for long-term observability and model improvement.
OpenTelemetry-Based Integration
This approach relies on OpenTelemetry, the open standard for collecting and exporting traces, metrics, and logs across distributed systems. You configure an OpenTelemetry collector and send your LLM traces to any compatible backend (Grafana, Datadog, Honeycomb, etc.).
Why it matters: Integration offers maximum flexibility and avoids vendor lock-in. You can integrate AI observability into your existing infrastructure rather than adopting a whole new platform.
Setup time: From a few days to several weeks, depending on your experience with OpenTelemetry.
Tradeoffs: The steepest learning curve and most configuration effort, but unmatched flexibility and control.
Best for: Teams with existing observability stacks or those building long-term, scalable AI systems.
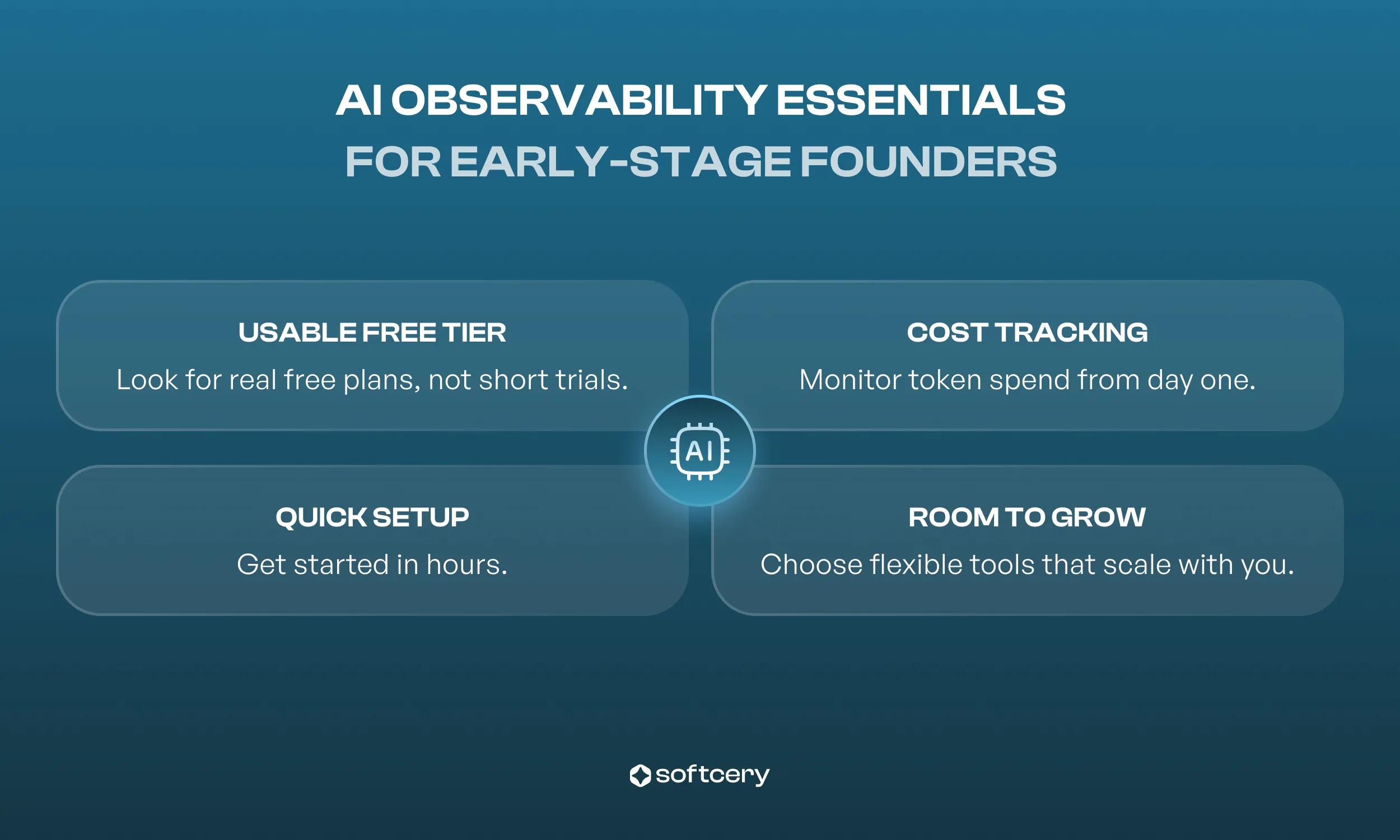
Advice for MVP-Stage Founders: What to Look For in AI Observability Tools
When you’re building your first AI-powered product, every week and every dollar matters. The right AI observability tool should help you monitor, debug, and scale without slowing you down.
-
A free tier you can actually use: Don’t settle for a “free trial” that expires in 14 days. Look for genuinely usable options. Pydantic Logfire provides 10M spans/month free. Braintrust offers 1M spans and 10K scores free. Phoenix is unlimited if self-hosted. Langfuse Cloud, which Softcery currently uses for new projects, is free for up to 50K events per month on the Hobby tier (and free if self-hosted). LangSmith offers 5K traces monthly. Helicone gives you 10K requests per month free.
-
Setup time under a week: Your observability stack shouldn’t become a side project. Pydantic Logfire and Phoenix can each be running in a few hours. Langfuse also falls into the “easy start” category: its SDK-based setup typically takes only a few hours and delivers rich prompt and trace analytics out of the box.
-
Cost tracking from day one: Token usage adds up fast, and it’s easy to lose track. Choose a platform that includes real-time cost monitoring and alerting. Most modern AI agent monitoring tools do, but don’t skip the setup, or your budget will pay for it later.
-
Room to grow: Start lightweight, but make sure you can evolve. For example, you can begin with Langfuse or Braintrust free tiers and later run Phoenix in parallel, or move from Phoenix to Arize AX for deeper performance analytics. Avoid solutions that lock you into one ecosystem early on.
9 Best AI Observability Platforms in 2026
Arize Phoenix
Leading open-source observability platform; enterprise upgrade via Arize AX.
- Core capabilities: Distributed tracing (OpenTelemetry), advanced evaluation (hallucination detection, relevance scoring), multi-step agent trajectory analysis, drift detection, supports 50+ LLMs and frameworks.
- Deployment: Docker (self-hosted), cloud free instance, enterprise with compliance, Copilot features, and Alyx AI assistant.
- Pricing: Open source FREE (self-hosted, user-managed infrastructure). AX Free: 25k spans/mo, 1 GB ingestion, 15-day retention. AX Pro: USD 50/mo, 50k spans/mo, 10 GB ingestion, 30-day retention. AX Enterprise: custom pricing with SOC2/HIPAA compliance and configurable limits.
- Integration: Framework/LLM agnostic, moderate code changes, setup 2–4 hrs for Docker, 1–2 weeks for production. Includes Prompt IDE for faster iteration.
- Strengths: Open source with no limits, production-ready, strong evaluation, clear enterprise upgrade path.
- Weaknesses: Requires technical setup, learning curve with OpenTelemetry, less focus on operational metrics.
- Best for: MVP-stage founders with technical teams seeking production-ready monitoring without vendor lock-in.
- Softcery recommends Langfuse based on our own experience: we currently use it for new projects because it’s easy to start with (cloud setup takes minutes) and offers a free tier which covers up to 50,000 events per month at no cost.
LangSmith
LangChain’s official observability platform with Fleet for enterprise agent management.
- Core capabilities: End-to-end tracing, prompt/tool capture, step-through debugging, token/latency/cost metrics, dataset management, prompt versioning. Fleet for agent identity, permissions, and dedicated Slack identities. Pairwise annotation queues, unified cost tracking across full agent workflows, multi-modal evaluator support, and Polly AI assistant for traces.
- Deployment: Cloud, hybrid (SaaS control plane + self-hosted data), enterprise self-hosted.
- Pricing: Free (1 seat, 5k traces/month), Plus USD 39/user/mo, base traces USD 2.50/1k (14-day retention), extended traces USD 5.00/1k (400-day retention), enterprise custom. Startup Plan available for early-stage companies with discounted rates.
- Integration: Native LangChain (minimal code changes), limited outside LangChain. Setup ~30 min. LangSmith Fetch CLI brings trace access into terminals and IDEs.
- Strengths: Best for LangChain users, excellent prompt management, dataset evaluation. Fleet adds enterprise-grade agent lifecycle management. - Weaknesses: LangChain lock-in, closed source, can be expensive at scale with per-trace pricing.
- Best for: MVP-stage founders deep in LangChain wanting fast, comprehensive visibility. The Startup Plan makes it more accessible for early-stage teams.
Helicone
Proxy-based observability with one-line integration. ⚠️ Acquired by Mintlify and transitioned to maintenance mode (security updates and bug fixes only). New feature development has stopped.

- Core capabilities: Logs requests/responses, caching, cost tracking, rate limiting, custom properties, 100+ LLMs supported, Anthropic prompt caching monitoring, Go SDK, and LangGraph integration.
- Deployment: Cloud (Cloudflare workers), self-hosted optional.
- Pricing: Free 10k requests/mo; Pro USD 79/mo; Team USD 799/mo (SOC-2, HIPAA). Startup discount available (50% off first year for companies under 2 years old with less than $5M in funding).
- Integration: Change API base URL; 15-min setup; 1–2 lines of code.
- Strengths: Fastest time-to-value for basic monitoring.
- Weaknesses: Maintenance mode, no new features planned. Limited evaluation, less depth than SDK-based, proxy dependency. Mintlify is integrating Helicone’s technology into its own knowledge infrastructure, so the platform’s long-term future is uncertain.
- Best for: Teams already using Helicone that don’t need new features. For new projects, consider Langfuse, Braintrust, or Pydantic Logfire instead.
Langfuse
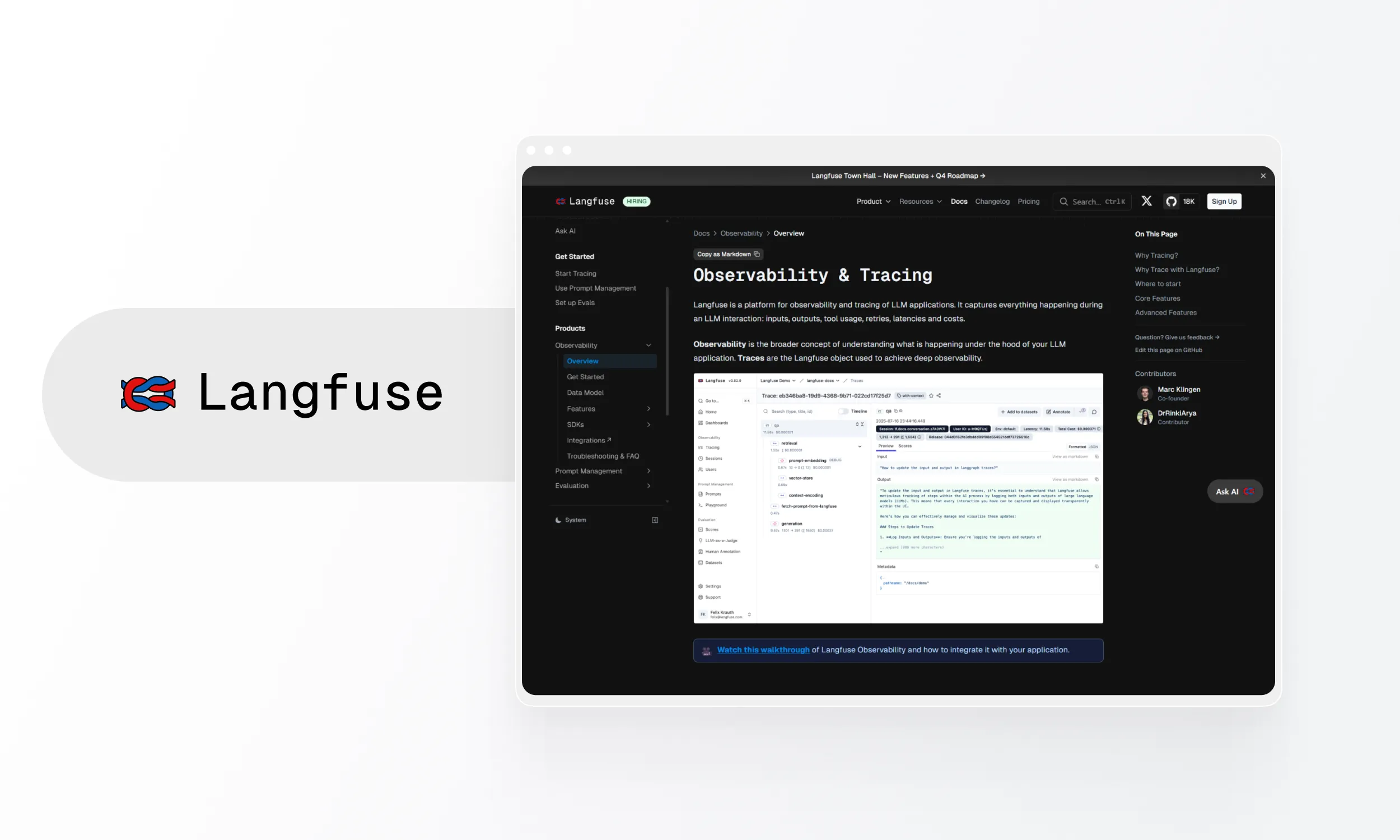
Open-source platform for prompt management and collaborative development. Acquired by ClickHouse in January 2026 as part of ClickHouse’s $400M Series D (valuing ClickHouse at $15B). MIT license preserved, no feature gates added.
- Core capabilities: Prompt tracking/versioning, execution traces, dataset evaluation, token/cost tracking, user feedback collection. Experiments as first-class concept, Boolean and Categorical LLM-as-a-Judge scores, Cloud Japan region.
- Deployment: Self-hosted (free, MIT license), cloud (tiered pricing, up to 50k events/month free). Requires ClickHouse, Redis, S3 for self-hosting.
- Pricing: Free self-hosted (MIT license). Cloud: Hobby FREE (up to 50k events/month), Core USD 29/mo, Pro USD 199/mo, Enterprise USD 2,499/mo.
- Integration: SDK-based, OpenTelemetry compatible; setup 4–8 hrs cloud, 1–2 weeks self-hosted.
- Strengths: Fully open source (MIT), strong prompt version control, collaborative features. ClickHouse backing adds long-term stability and infrastructure expertise. 20,470+ GitHub stars, 26M+ SDK installs/month, used by 19 of Fortune 50.
- Weaknesses: Complex infrastructure for self-hosting, cloud paid tier expensive.
- Best for: Teams focused on prompt engineering and iterative development. Pricing tiers cover every stage from solo founder to enterprise.
- Softcery recommends: Langfuse is the platform Softcery actively uses for new projects. It’s easy to start with, free up to 50k events/month on free plan, may be scaled to Core at USD 29/mo when needed.
Datadog LLM Observability
Enterprise APM vendor’s specialized LLM monitoring.

- Core capabilities: Full-stack tracing, latency/cost/error metrics, security scanning, hallucination/drift detection, CI/CD integration, integrated support for OpenAI, LangChain, AWS Bedrock, and Anthropic frameworks via Python SDK.
- Deployment: Cloud-only SaaS; integrates with existing Datadog.
- Pricing: Enterprise only, contact sales. Bills based on LLM span count. Includes bundled Sensitive Data Scanner.
- Strengths: Comprehensive integration, strong security/compliance, correlates with infrastructure metrics.
- Weaknesses: Expensive, overkill for startups, cloud-only.
- Best for: Post-MVP/enterprise companies with Datadog.
AgentOps
Python SDK for AI agent monitoring with time-travel debugging.
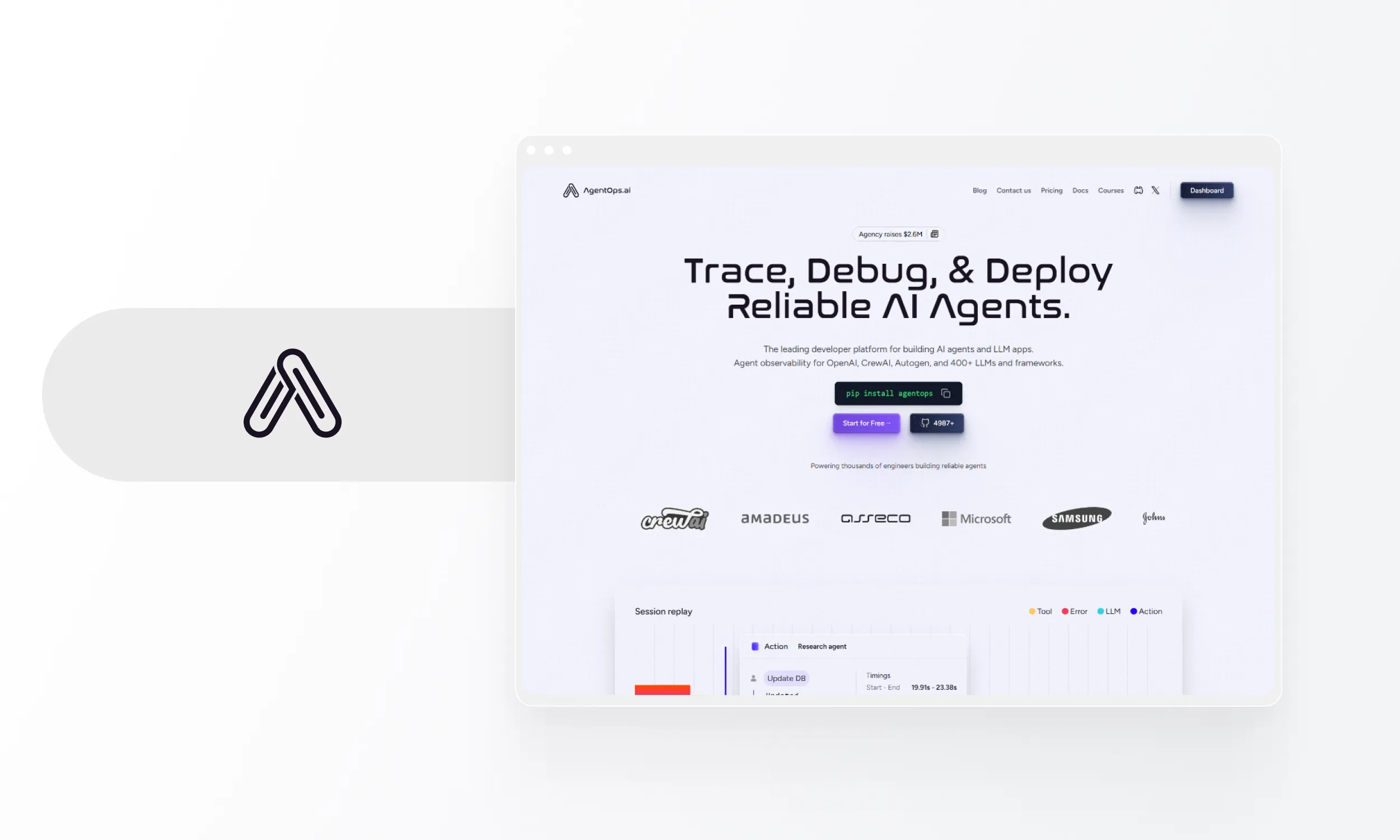
- Core capabilities: Visual event tracking, session replay, cost tracking, full data trail, multi-agent support. Native OpenAI Agents SDK integration (Python and TypeScript), CrewAI, AutoGen, and LangGraph support.
- Deployment: Cloud-only.
- Pricing: Free trial 1k events, Pro USD 40/mo (unlimited events and log retention), enterprise custom.
- Integration: Python SDK, 1 hr setup, moderate code changes.
- Strengths: Specialized for agent workflows, time-travel debugging, good cost tracking.
- Weaknesses: Smaller ecosystem and limited funding (USD 2.6M pre-seed) compared to competitors like Braintrust (USD 80M) and Langfuse. Limited evaluation features.
- Best for: Python developers building multi-agent systems needing deep debugging.
Braintrust
Evaluation and observability platform backed by an $80M Series B at $800M valuation, led by ICONIQ with Andreessen Horowitz and Greylock participating.
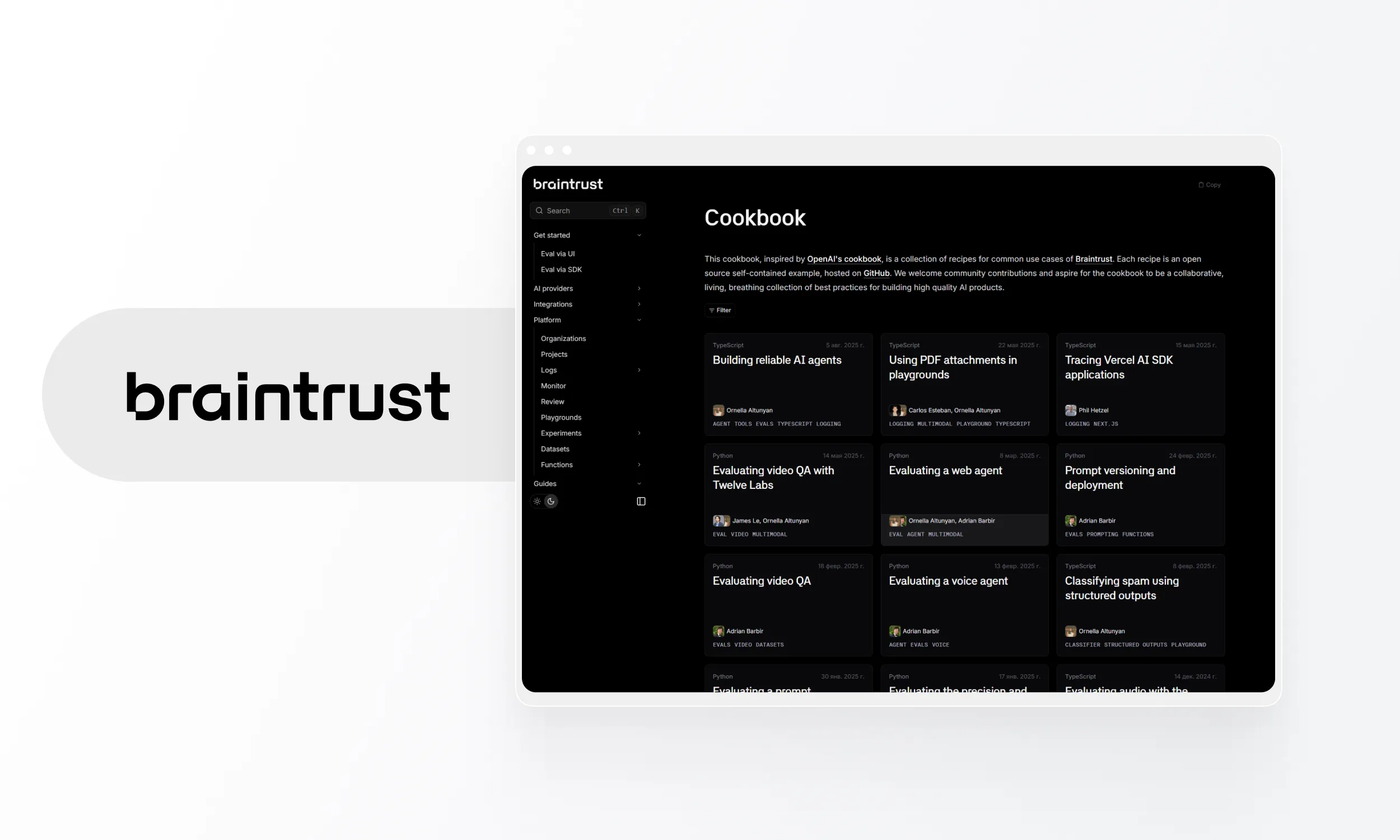
- Core capabilities: Dataset evaluation, prompt/model A/B testing, Loop AI agent for automated optimization and natural language queries over production data, automatic dataset generation, Brainstore DB, production monitoring. Native SDK support for 13+ frameworks including OpenAI Agents SDK, Google ADK, Pydantic AI, Mastra.
- Deployment: Cloud, hybrid for enterprise.
- Pricing: Free tier includes 1M spans and 10K scores (one of the most generous free tiers available). Pro USD 249/mo with unlimited spans and scores. Enterprise custom.
- Strengths: Strong evaluation, automated prompt optimization, fast queries. Major enterprise customers: Notion, Stripe, Vercel, Airtable, Instacart, Zapier, Ramp, Dropbox, Cloudflare.
- Weaknesses: More evaluation than monitoring. Still evolving its real-time operational monitoring compared to dedicated platforms.
- Best for: Teams prioritizing systematic evaluation, or anyone needing a generous free tier. The $80M in funding and enterprise customer base signal long-term stability.
Lunary
Production toolkit with security focus and automatic output categorisation.
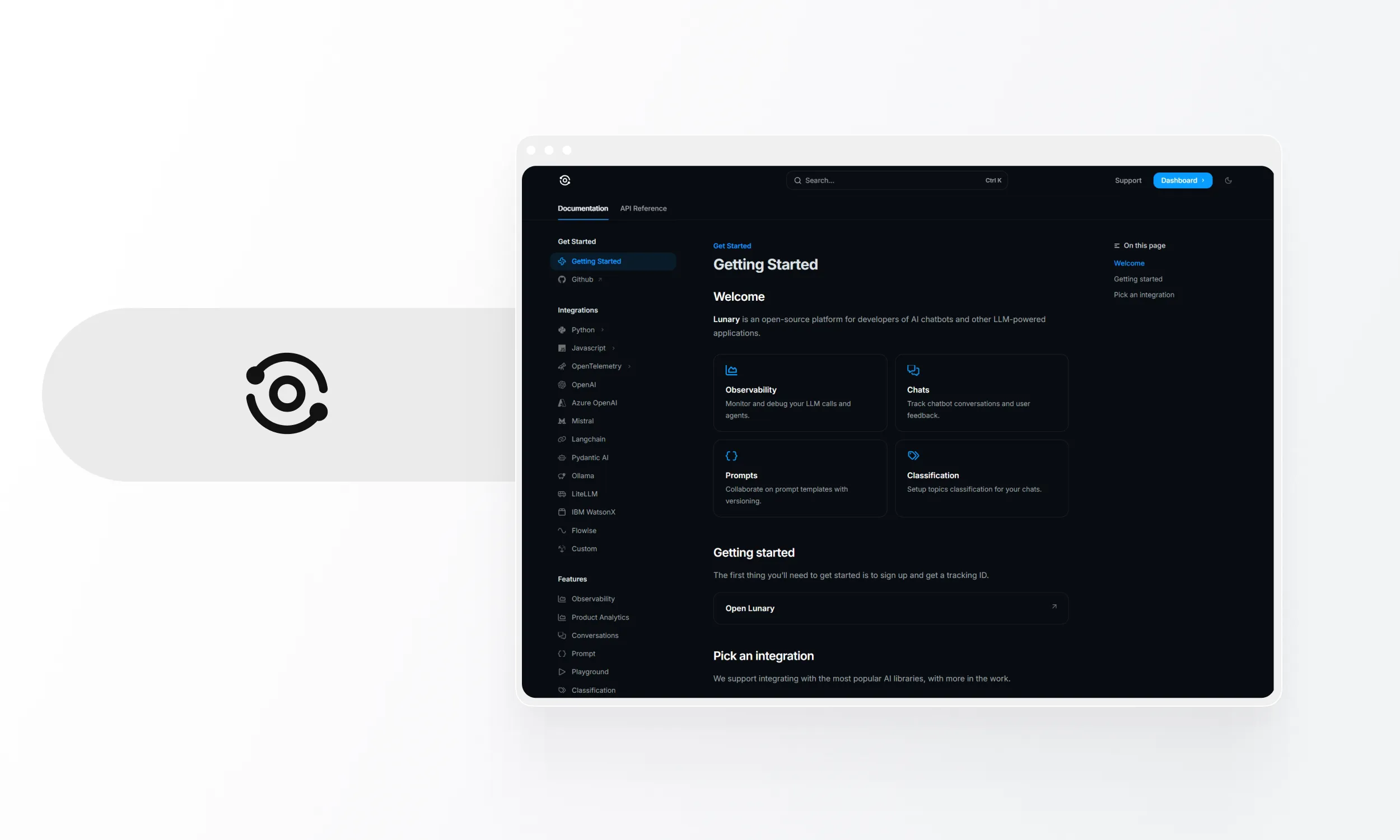
- Core capabilities: Conversation/feedback tracking, real-time analytics, prompt versioning, auto-categorisation (Radar), dashboards, LLM firewalls, PII masking.
- Deployment: Hosted cloud or self-hosted.
- Pricing: Free 10k events/mo; Team USD 20/user/mo.
- Strengths: Unique auto-categorisation, strong security/compliance, easy setup.
- Weaknesses: Smaller community, limited features vs. enterprise, free tier limited.
- Best for: MVP-stage teams needing affordable monitoring with security/PII handling.
Pydantic Logfire
Full-stack observability platform built on OpenTelemetry, from the creators of Pydantic.
- Core capabilities: Traces entire application stack (not just LLM calls), OpenTelemetry-native, structured query language, live tail for real-time debugging, integrates with Pydantic Evals for AI-specific evaluation. Covers HTTP requests, database queries, and LLM calls in a single trace.
- Deployment: Cloud SaaS. OpenTelemetry standard means data can also be exported to self-hosted backends.
- Pricing: Personal FREE (10M spans/month, 1 seat, 30-day retention). Team USD 49/mo (5 seats included, USD 25/additional seat). Growth USD 249/mo (unlimited seats, up to 90-day retention, priority support). Enterprise custom. Overage at USD 2/M additional records on paid tiers.
- Integration: Python, JavaScript, and Rust SDKs. Simple decorator-based instrumentation. Setup in 1–2 hours. OpenTelemetry compatibility means it works alongside existing observability infrastructure.
- Strengths: Full-stack visibility beyond just LLM calls. OpenTelemetry-native avoids vendor lock-in. Extremely generous free tier. Natural fit for teams already using Pydantic (common in Python AI development). Active development from a well-established open-source team.
- Weaknesses: Newer platform with a smaller community than Phoenix or Langfuse. Less LLM-specific evaluation tooling compared to Braintrust or Phoenix.
- Best for: Python teams wanting full-stack observability that includes AI alongside application traces. Teams already using Pydantic. Anyone prioritizing OpenTelemetry-native tooling with a generous free tier.
AI Agent Observability Decision Framework
Use this framework to quickly pinpoint the tools that match your needs and get your AI systems running reliably from day one.
Choose Based on Your Primary Need
Cost Tracking & Optimisation:
- Langfuse: Strong prompt engineering focus with cloud tiers starting free (50K events/month). Softcery actively uses and recommends it for new MVPs.
- Braintrust: 1M free spans with built-in cost tracking across evaluated outputs. Transparent pricing.
- Pydantic Logfire: 10M spans/month free, tracks costs across the full application stack.
- AgentOps: Tracks 400+ LLMs, cost optimisation features, claims 25x reduction in fine-tuning costs.
Why: Prevent surprise bills, optimise token usage patterns.
LangChain Workflows:
- LangSmith: 30 minutes setup if using LangChain.
Why: Native integration, best debugging experience, zero code changes. Tradeoff: Framework lock-in, limited value if you switch away from LangChain.
Evaluation-First Approach:
- Braintrust: Loop AI agent for automated optimisation, systematic dataset evaluation.
- Confident AI: 40+ research-backed metrics, component-level evaluation.
Why: Systematic testing, quality metrics, regression detection. Tradeoff: Less focus on operational monitoring.
Self-Hosted / No Vendor Lock-in:
- Phoenix: Easier setup (single Docker container), OpenTelemetry standard, strong evaluation.
- Langfuse: Better prompt management, MIT license preserved, collaborative features.
- Pydantic Logfire: OpenTelemetry-native, data can be exported to any compatible backend.
Why: Control over data, no recurring platform costs, avoid vendor lock-in. Tradeoff: Infrastructure management overhead.
Agent-Specific Debugging:
- AgentOps: Time-travel debugging, multi-agent workflow visualisation, session replay.
Tradeoff: Python-only, cloud-only, smaller ecosystem.
Enterprise Compliance:
- HoneyHive / Arize AX: SOC 2, HIPAA, GDPR compliance out of the box, enterprise deployment options.
Tradeoff: Expensive (USD 50k+/year), longer sales cycles.
Existing Observability Stack:
- OpenLIT / Traceloop: Works with Prometheus/Grafana/Jaeger, OpenTelemetry standard, no new platform to learn.
Tradeoff: More configuration needed, less LLM-specific features.
Choose Based on Your Budget
USD 0 (Open Source / Free Tiers):
- Braintrust: 1M spans and 10K scores free, the most generous free tier for evaluation-focused teams
- Pydantic Logfire: 10M spans/month free, the most generous span-based free tier
- Phoenix: Best overall self-hosted, production-ready, strong evaluation
- Langfuse: Free cloud tier for getting started and free self-hosted option with best prompt engineering features
- OpenLIT: If you have existing Prometheus/Grafana
Tradeoff: Self-hosted options require infrastructure management (expect USD 50-500/mo for hosting). Cloud free tiers have usage limits.
<USD 100/mo:
- Langfuse Core: USD 29/mo, strong prompt management, cloud-managed
- AgentOps Pro: USD 40/mo, unlimited events, time-travel debugging
- Pydantic Logfire Team: USD 49/mo, 5 seats, 10M spans included
- Lunary Team: USD 20/user/mo, security features
Best for: Solo founders, small teams with modest request volumes.
USD 100-500/mo:
- Langfuse Pro: USD 199/mo, full features, managed
- Braintrust Pro: USD 249/mo, unlimited spans and scores, strong evaluation
- LangSmith Plus: USD 39/user/mo for small teams (5-10 people)
Best for: Small technical teams scaling past MVP.
USD 500-2k/mo:
- Langfuse Enterprise: USD 2,499/mo, full support
- LangSmith: for larger teams with trace volume costs
- Phoenix self-hosted: with production infrastructure
Best for: Post-MVP companies (10-100 customers), Series A stage.
USD 2k+/mo:
- HoneyHive, Arize AX, Datadog: Enterprise solutions
- Multiple specialized tools: Best-of-breed stack
Best for: Series A+ companies with enterprise customers. Not recommended for MVP-stage unless compliance requirements force it.
Choose Based on Your Team
Solo Founder:
- Langfuse Cloud: easy setup, managed infrastructure, free to start
- Alternative: Pydantic Logfire if already using Pydantic, or Phoenix if comfortable with Docker
Why: Minimize time on infrastructure, maximize time on product.
Small Technical Team (2-5 engineers):
- Phoenix: self-hosted, team can manage infrastructure
- Alternative: Braintrust for evaluation-first approach with generous free tier
Why: Technical capability to self-host, benefit from cost savings.
Non-Technical Team:
- LangSmith (if using LangChain) or Langfuse Cloud (simplest overall)
- Avoid: Self-hosted solutions requiring infrastructure management
Why: Managed service, support available, simple setup.
DevOps Capable:
- Phoenix + Langfuse: best of both worlds
- Alternative: OpenLIT integrate with existing observability
Why: Can handle infrastructure complexity, want maximum features and control.
Enterprise Team:
- HoneyHive, Arize AX, Datadog: enterprise solutions
Why: Compliance features, dedicated support, enterprise SLAs.
Choose Based on Your Timeline
Need It Today:
- Helicone: 15 minutes to monitoring (note: now in maintenance mode, functional but no new features)
- Pydantic Logfire: 1–2 hours, full-stack traces from the start
- Verify logs appearing, set cost alerts
This Week:
- LangSmith: 30 minutes (LangChain users)
- AgentOps: 1 hour
- Production-ready by end of week
This Month:
- Phoenix: 2-4 hours setup, 1 week to production-ready
- Langfuse: 4-8 hours to 1-2 weeks for infrastructure
- Time for proper testing, alerts, dashboards
Enterprise Rollout:
- HoneyHive, Datadog: 1-4 weeks
- Sales process, evaluation, integration
- Training, rollout, optimisation
Key Takeaways
1. Observability Isn’t Optional
AI agents fail differently than traditional software: outputs vary, reasoning chains break, costs spike, security risks appear. Without monitoring, the first signal is customer complaints; debugging takes days. Add observability before launch, not after. A one-week setup prevents weeks of firefighting.
2. Production-Ready Options Exist for Every Budget
Free tiers have become genuinely usable: Braintrust offers 1M spans free, Pydantic Logfire 10M spans/month, Phoenix is unlimited self-hosted, and Langfuse has a free Hobby tier. Enterprise options include Datadog, Arize AX, and HoneyHive.
3. Start Simple, Upgrade Later
Basic monitoring catches 90% of issues. Pydantic Logfire takes 1–2 hours, Phoenix 2–4 hours. Add complexity only when needed. Upgrade paths exist: Langfuse Hobby → Langfuse Pro → enterprise solutions. Note that Helicone entered maintenance mode, so it’s no longer recommended as a starting point for new projects.
4. Cost Tracking Pays for Itself
Observability platforms cost USD 0–500/mo for most startups. Monitoring token usage and query patterns saves hundreds to thousands. Catch expensive patterns before they hit your bill.
Frequently Asked Questions
Yes. Adding observability before launch takes one week. Debugging production issues without it takes weeks. When a customer reports “the agent gave me wrong information yesterday,” you need to see exactly what happened. Without traces, you’re guessing based on vague descriptions.
Free options exist (Braintrust offers 1M spans free, Pydantic Logfire 10M spans/month, Phoenix is unlimited self-hosted, Langfuse has up to 50K events/month free). Budget isn’t an excuse. The gap between demo-ready and production-ready is where observability matters.
- Pre-MVP: USD 0 (Braintrust Free, Pydantic Logfire Free, or Phoenix self-hosted)
- MVP to early traction: USD 25-250/mo (Langfuse Core at USD 29/mo or Braintrust Pro at USD 249/mo for heavier usage)
- Scaling (100+ customers): USD 500-2,500/mo (managed solutions or production self-hosted)
- Series A+: USD 2,000-10,000/mo (enterprise compliance requirements) Cost optimization through observability often saves more than the platform costs. Identifying expensive query patterns saves thousands.
Monitoring tracks operational metrics: Did requests succeed? How long did they take? What did they cost? Tells you something broke.
Evaluation measures quality: Is the output accurate? Is it relevant? Are there hallucinations? Tells you why quality dropped.
AI agents need both. Monitoring keeps system running. Evaluation keeps system correct. Most platforms offer both, but emphasis varies (Pydantic Logfire focuses on full-stack monitoring, Braintrust focuses on evaluation, Phoenix balances both).
Choose SaaS if:
- Solo founder or small team without DevOps capacity
- Need fastest possible setup (launch this week)
- Prefer predictable costs over infrastructure management
- Don’t have data sovereignty requirements
Choose self-hosted if:
- Technical team comfortable with Docker/infrastructure
- Want to avoid recurring platform costs (USD 25-500/mo → USD 50-200/mo infrastructure)
- Have compliance requirements (data can’t leave your infrastructure)
- Want maximum control and no vendor lock-in
Both are production-ready. Phoenix self-hosted is as reliable as commercial SaaS once properly deployed.
Core needs are the same (cost tracking, traces, quality evaluation), but voice agents add:
- Real-time requirements: Voice needs <500ms response latency. Monitor p95/p99 latency carefully.
- Multi-modal traces: Track STT (speech-to-text), LLM reasoning, TTS (text-to-speech) as separate steps. Need observability that handles this pipeline.
- Audio-specific metrics: STT accuracy, TTS naturalness, interrupt handling, turn-taking patterns.
All major platforms (Phoenix, LangSmith, Langfuse, Pydantic Logfire) handle voice agents. Focus on latency monitoring and cost tracking across the full STT-LLM-TTS pipeline.






































