
[ Voice AI Model Fine-Tuning (LLM, TTS, STT) ]
Tune every model in the stack until the agent gets it right.
LLM behavior, STT for your accents and vocabulary, and TTS voice quality, improved through evaluation, so every change is measured, not guessed.
[ Why fine-tuning ]
Generic models fail on the calls that matter most.
The hard accent, the industry term, the policy edge case: that's where off-the-shelf models break. And benchmarks lie: a model that wins on offline test sets can lose in streaming conditions, where voice agents actually live. We don't fine-tune because it sounds advanced. We diagnose what's failing (recognition, reasoning, voice, or escalation) and choose the lightest method that reliably fixes it.
- The hard accent
- Real phone audio the model was never tuned for, misheard call after call.
- The industry term
- Names, products, and jargon transcribed wrong, then reasoned over wrong.
- The policy edge case
- The rare path off-the-shelf behavior was never trained to handle.
[ What gets tuned ]
Every layer in the stack is improvable.
Open speech models now match top commercial APIs on accuracy – streaming recognition reaches 7-8% word error rates, on par with the best paid services – and unlike APIs, they can be fine-tuned on your domain.
| Layer | What tuning fixes |
|---|---|
| LLM | Reasoning, answer style, policy handling, escalation, and safe responses. |
| STT | Accents, noisy calls, industry terms, names, locations, and domain vocabulary. |
| TTS | Voice, pronunciation, speed, warmth, clarity, and consistency. |
| Conversation logic | Flow, interruptions, confirmations, fallback paths, and human handoff. |
| Knowledge | Grounding in FAQs, policies, service rules, and product data. |
| Safety | Refusal logic, sensitive-topic handling, and compliance guardrails. |
[ Approach ladder ]
Use the lightest approach that works.
Fine-tuning is powerful, but it's not always the answer. We start with configuration and grounding, and only fine-tune where configuration genuinely can't reach.
| Approach | When it is enough |
|---|---|
| Prompt and workflow configuration | Most business voice agents. |
| Retrieval / knowledge grounding | When answers depend on policies, documents, or business data. |
| Speech adaptation and pronunciation dictionaries | Names, product terms, and domain vocabulary. |
| Evaluation-based iteration | When quality needs systematic improvement. |
| Fine-tuning | When repeated domain behavior cannot be solved through configuration. |
| Custom STT/TTS work | When accents, terminology, or voice quality are critical. |
[ The cold-start path ]
Fine-tuning needs data that doesn't exist before launch.
Real-time voice has a latency budget large models can't meet, and the small models that can need domain adaptation first. The staged path solves both: launch without training data and let production traffic build the dataset – with clean, validated synthetic data closing the gap where it's good enough to.
| Stage | What happens |
|---|---|
| Launch | A strong general model runs the agent through an API. No training data needed on day one. |
| Instrument | Every conversation is logged and scored from the first call: this is tomorrow's training data. |
| Baseline | Small open models are benched against the incumbent on latency, quality, and tool calling – so the roadmap starts from a measured floor, not assumptions. |
| Fine-tune | The small model is adapted to the domain: terminology, tool calling, conversation policy. Where real conversations are still scarce, carefully validated synthetic data bootstraps the first round – real traffic then refines it. |
| Migrate | The tuned model replaces the API behind evaluation gates, cutting both latency and per-call cost. |
[ Evaluation loop ]
Quality you can measure.
- Sample call sets that reflect real traffic
- Accent and domain-vocabulary testing
- Benchmarks on production-class GPUs under concurrent load, not single-stream demos
- Stall tracking at the audio-frame level: any gap long enough to hear counts against the model
- Latency and escalation testing
- Hallucination and safety checks
- Conversation scoring against a rubric
- Ear tests alongside metrics: voice consistency review by humans
- Before/after measurement on every change
[ When tuning is worth it ]
The symptoms tuning fixes.
Misheard domain terms
Names, products, and jargon transcribed wrong, call after call.
Accents and noisy calls
Recognition quality drops on real phone audio.
Inconsistent answers
The same question gets different answers on different calls.
Unstructured outputs
Summaries too messy for your CRM or case records.
Off-brand voice
Wrong tone, mispronounced names, inconsistency across languages.
Unreliable escalation
Calls that should reach a human don't, or do too often.
[ Voice and consent ]
Custom voices, done responsibly.
- Custom TTS voice design and approved brand voice
- Zero-shot cloning needs only seconds of reference audio – which is exactly why consent comes first
- Pronunciation dictionaries for names and terms
- Voice consistency across languages
- Voice cloning only with documented consent and usage rights
- License vetting: many open speech models carry non-commercial weights or lock serving features behind paid containers
- Voice economics, stated upfront: cloning-capable models can cost multiples more per concurrent stream than fixed-voice ones
- Data-use limits, retention rules, and auditability
- No unauthorized cloning: a designed brand voice is often the safer path
[ Engagement shapes ]
Scoped to the problem, not the buzzword.
| Engagement | Best for |
|---|---|
| Quality diagnosis | An existing agent with accuracy or behavior problems. |
| Speech optimization sprint | STT errors: accents, domain terms, noisy calls. |
| LLM behavior tuning sprint | Inconsistent answers, bad summaries, routing issues. |
| Voice & brand customization | An agent that needs to sound like your brand. |
| Continuous quality program | Production agents that need ongoing improvement. |
[ How tuning runs ]
Diagnosis first. Measurement always.
-
3–5 days
Diagnose
Review real calls and find the failing layer: recognition, reasoning, voice, or logic.
-
1–2 weeks
Baseline
Build an evaluation set that reflects real traffic, and measure before touching anything.
-
1–3 weeks
Tune
Apply the lightest method that works: configuration, grounding, adaptation, or fine-tuning.
-
~1 week
Validate
Regression-test against the baseline. Ship only measured improvement.
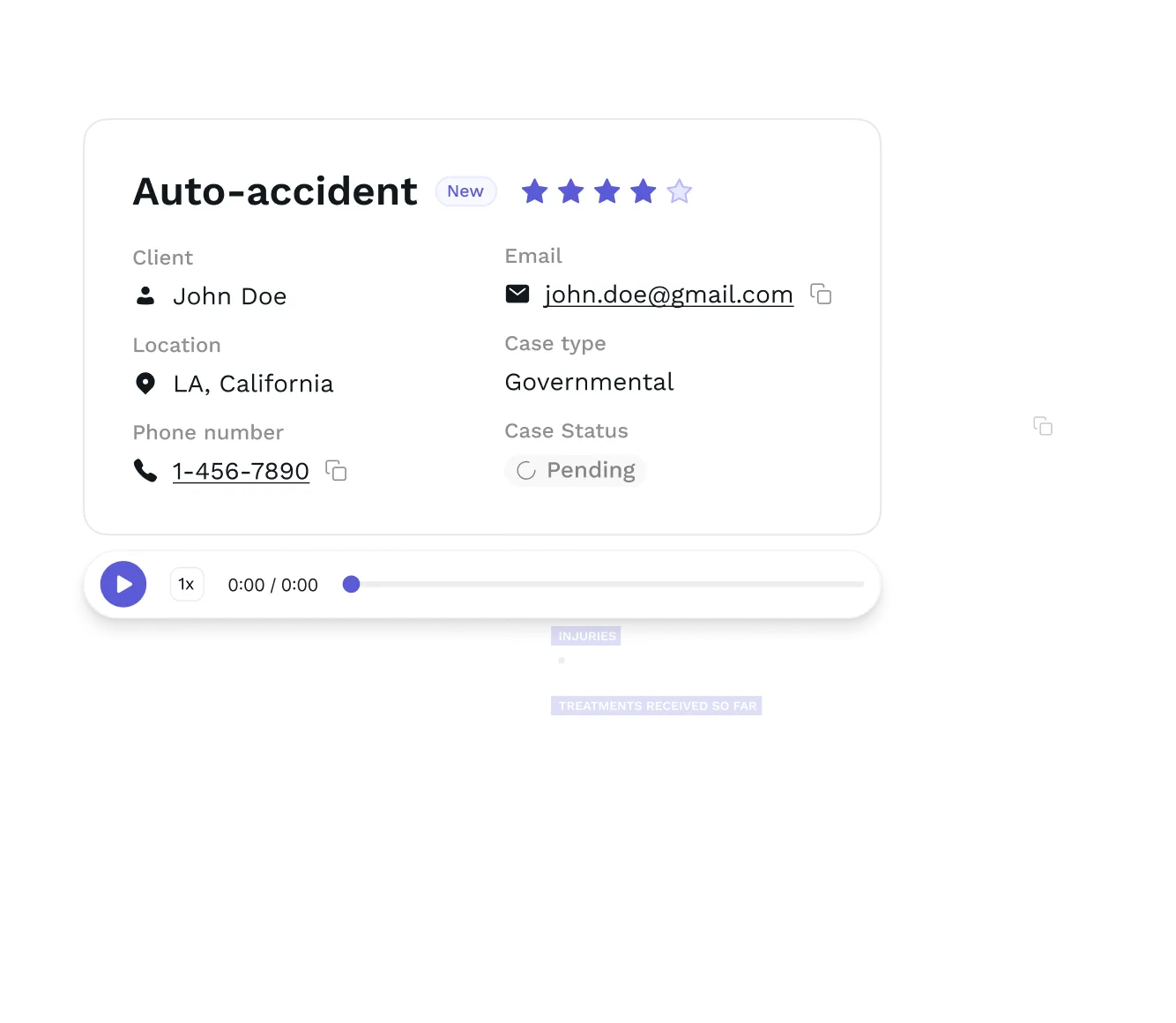
[ Proven in production ]
Model work we've shipped.
Where evaluation, speech tuning, and regression testing decided whether the agent held up on real calls.


[ Common questions ]
Asked before most tuning work.
| Question | Answer |
|---|---|
| Do all voice agents need fine-tuning? | No. Most issues resolve with prompting, retrieval, or speech adaptation. True fine-tuning is the last resort, not the first. |
| Can you clone our CEO's voice? | Only with documented consent and usage rights. For most cases a designed brand voice is safer and easier to manage. |
| Can it handle accents, noisy calls, and our industry terminology? | Yes. Accents and noise are STT-layer work: adaptation, vocabulary boosting, or custom training, validated on your real audio. Terminology – legal, medical, hospitality, product names – is tuned on both the recognition and reasoning layers. |
| Why fine-tune a small model instead of using the biggest one? | Real-time voice gives the whole listen-think-speak loop about a second. Large models are too slow and too expensive per call; a small model fine-tuned on your domain fits the budget and matches them where it counts: terminology, tool calling, and policy. |
| How do you prove it improved? | Before/after measurement on a fixed evaluation set: recognition accuracy, intent accuracy, and call outcomes. |
6 yrs
in complex B2B software
20+
experts across AI, product, design, and engineering
4.9/5
average client satisfaction
5+
industries: SaaS, hospitality, LegalTech, MarTech, support

"What truly stood out was Softcery's deep AI expertise. They were able to take our vision and turn it into a reality, and the final product has exceeded our expectations. Working with Softcery has been a game-changer for our business."

Jeanette Kreft
Managing Director, The Compliance Company & Upskill AI
"Softcery is not your typical software development agency – they're a full-scale product consultancy. The benefit of working with them is the collaboration."

Ryan Tabb
Founder, Bullseye