Vive Health: From Inbox to Resolved Case, Automatically
Last updated on June 5, 2026
We build and advise on production AI systems. Bring your questions to a free intro call.
Talk to usThousands of requests every month. Orders, quotes, returns, status questions, complaints, arriving by email, through the helpdesk, buried in forwarded threads, attached as PDFs and photos. Every one of them starts the same manual chain: read it, figure out what the customer actually wants, look them up in the system, check their account, draft a reply, decide the next step, follow up, and write it all down.
Vive Health sells medical equipment across the US – wheelchairs, braces, therapy supplies. Thousands of orders flow through Amazon daily. Another stream comes from their direct B2B platform, where healthcare providers and retailers buy in volume. Both channels generate a constant flow of requests. Most aren’t questions a chatbot can answer – they’re cases that need to be understood, acted on, and closed.
The team was doing all of it by hand. And the work didn’t scale the way the business did.
They came to us to change that.
The Problem: These Aren’t Tickets, They’re Cases
A chatbot answers a question and walks away. An inbox collects messages. A ticketing system tracks that a problem exists. None of that resolves anything. Vive needed something that could take a request from first contact all the way to done.
Before the AI agent, that gap created five interconnected problems.
Requests were scattered and unstructured. The same case might live half in an email, half in a forwarded thread, with the order details sitting in an attached PO. Someone had to assemble the full picture by hand before any work could begin.
Customers gave incomplete information. They referenced “my order” with no identifier. They described products by name instead of SKU. They left out the address, the quantity, the account. Every gap meant another round-trip before anything could move.
Response quality varied. With a team spread across skill levels and time zones, the same request could get a polished answer or one with errors that made business clients question the company’s professionalism.
There was no safe way to let automation act. Generic AI tools could draft text, but nobody could trust them to touch a real order, quote a real customer, or send a real reply without a human standing over them.
Failures were invisible. When something went wrong, there was no log, no trace, no way to understand why – so nothing got systematically better.
The result: a team that couldn’t fully trust automation, and tooling that couldn’t be trusted to run on its own.
Why Real Customer Operations Are Harder Than a Chatbot
Most AI support demos show a tidy FAQ exchange. Real customer operations look nothing like that.
The answer lives in business systems, not the message. To handle an order, the agent has to look the customer up, read their payment terms, check for overdue balances, and search the product catalog. The conversation is only the trigger – the work happens against the system of record.
Requests carry documents. A purchase order arrives as a PDF or a photo. The company name, PO number, ship-to address, SKUs, quantities, and prices all have to be pulled out of an unstructured attachment before anything can be created.
Intent is ambiguous and stakes are real. “I want a quote” and “where’s my order” branch into completely different workflows. A wrong answer about a return can cost a sale. A quote sent to an account with an overdue balance creates a problem downstream. Business clients with volume accounts demand higher accuracy than one-off consumers.
These constraints shaped every decision we made.
Turning Every Request Into a Structured Case
The first job of the agent isn’t to reply – it’s to understand. Every incoming request becomes a structured case before anything else happens.
Intent, category, and priority detection. The agent reads the request and classifies it – an order, a quote request, a return, a status question, a complaint – judges how urgent it is, then routes it into the right workflow. An order ticket triggers the quotation flow; a status question takes a different path entirely; an account at risk gets pushed up the queue.
Identifier and document extraction. Order numbers arrive in every format imaginable, often buried in email threads, frequently with extra characters. The agent recognizes and cleans them, and validates them against the system before using them. When a request carries a PO as a PDF or image, it parses out the company name, PO number, ship-to address, and every line item with its SKU, quantity, and price.
Missing-information detection. Before acting, the agent checks whether the case is actually complete. No address? No usable identifier? A product it can’t match? It flags exactly what’s missing instead of guessing – and asks for it, rather than hallucinating an answer.
A clean summary for the team. Each case carries a short, structured summary so a human can grasp it in seconds rather than re-reading the whole thread.
Deciding the Next Best Action
Once a request is a structured case, the agent decides what should happen next – and prepares it.
For an order, that means a chain of real steps: parse the PO, look the customer up in Odoo, verify their payment terms, check for overdue invoices that should block processing, read internal notes for special handling, then create a draft quotation with the correct customer, terms, delivery address, and matched line items – and post the result back into the case for review.
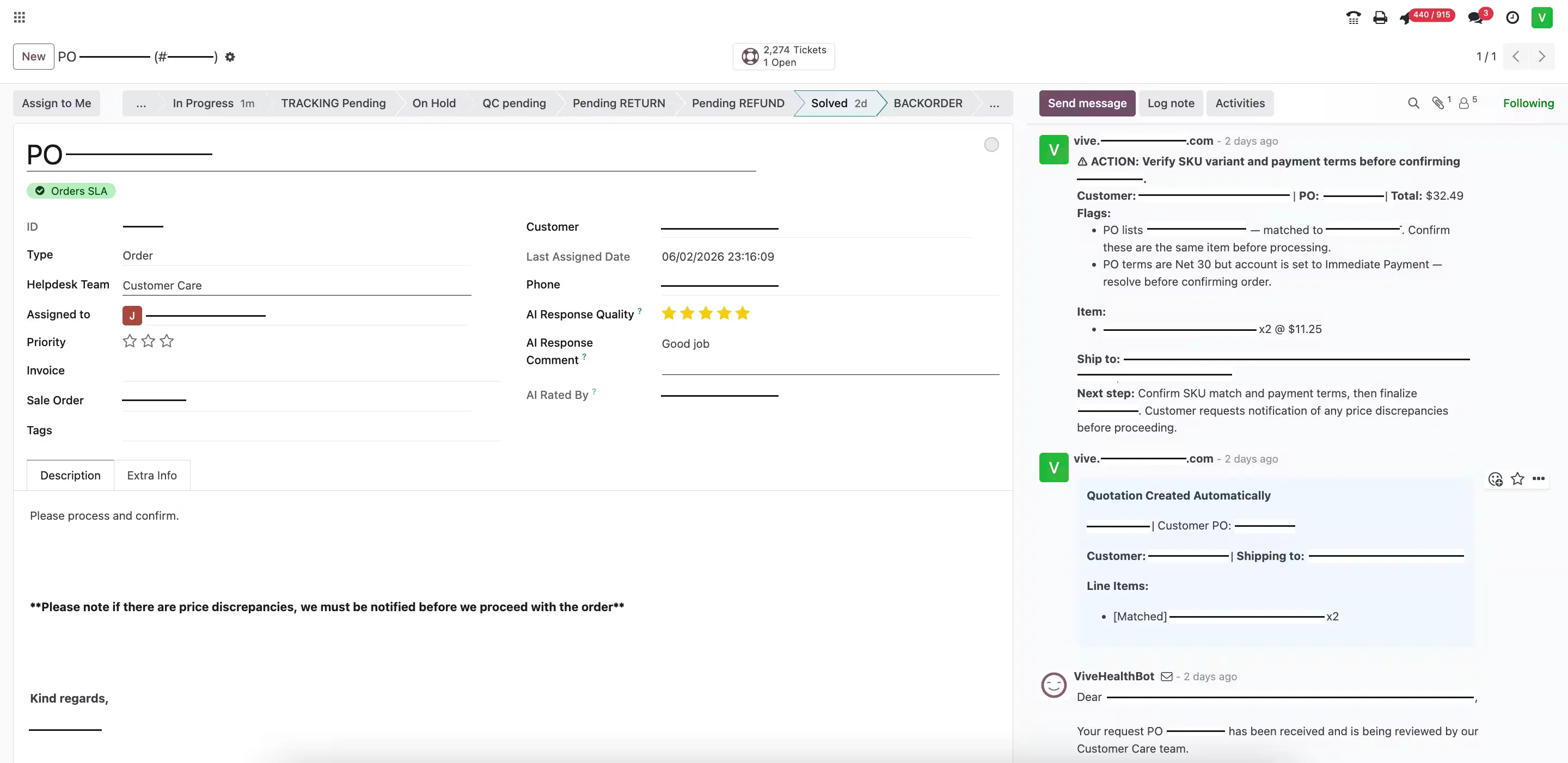
Context from past cases. Before it decides, the agent pulls up previous similar cases – this customer’s earlier orders, how a comparable request was handled, what was promised last time. That history grounds the decision: it disambiguates a vague product reference against what the customer actually bought before, keeps pricing and terms consistent with what they’ve already seen, and lets the agent continue a thread instead of treating every message as if it arrived from nowhere. Continuity across cases is what separates an agent that remembers from one that starts over every time.
Semantic product matching. Customers rarely use exact catalog names. They write “3-in-1 step-down LSO brace” instead of the SKU. The agent uses vector search over the product catalog to find the right match – and it knows when it isn’t sure. High-confidence matches are applied automatically; low-confidence ones are flagged for a person to confirm.
Graceful failure, never silent failure. If a product can’t be found, a customer can’t be matched, or an account has an overdue balance, the agent flags the specific issue on the case. It never quietly does the wrong thing.
For everything else, the next best action might be drafting a reply, asking for the missing detail, escalating to the right person, or scheduling a follow-up so an open case never falls through the cracks.
The Automation Ladder, Built for Trust
The hardest part of automating customer operations isn’t the AI – it’s earning the right to let it act. We didn’t flip a switch. We climbed a ladder, one rung at a time, with the team in control the whole way.
Rung one: silent monitoring. Before the agent touched a single live request, it ran in the background on real tickets, generating responses that were never sent. We compared its output against what the team actually did and learned where it was strong and where it broke – with zero risk to customers.
Rung two: suggestions a human sends. Next, the agent began drafting replies and posting them as internal suggestions inside the helpdesk. Staff reviewed, edited, and sent. The agent did the work; the human stayed the final word.
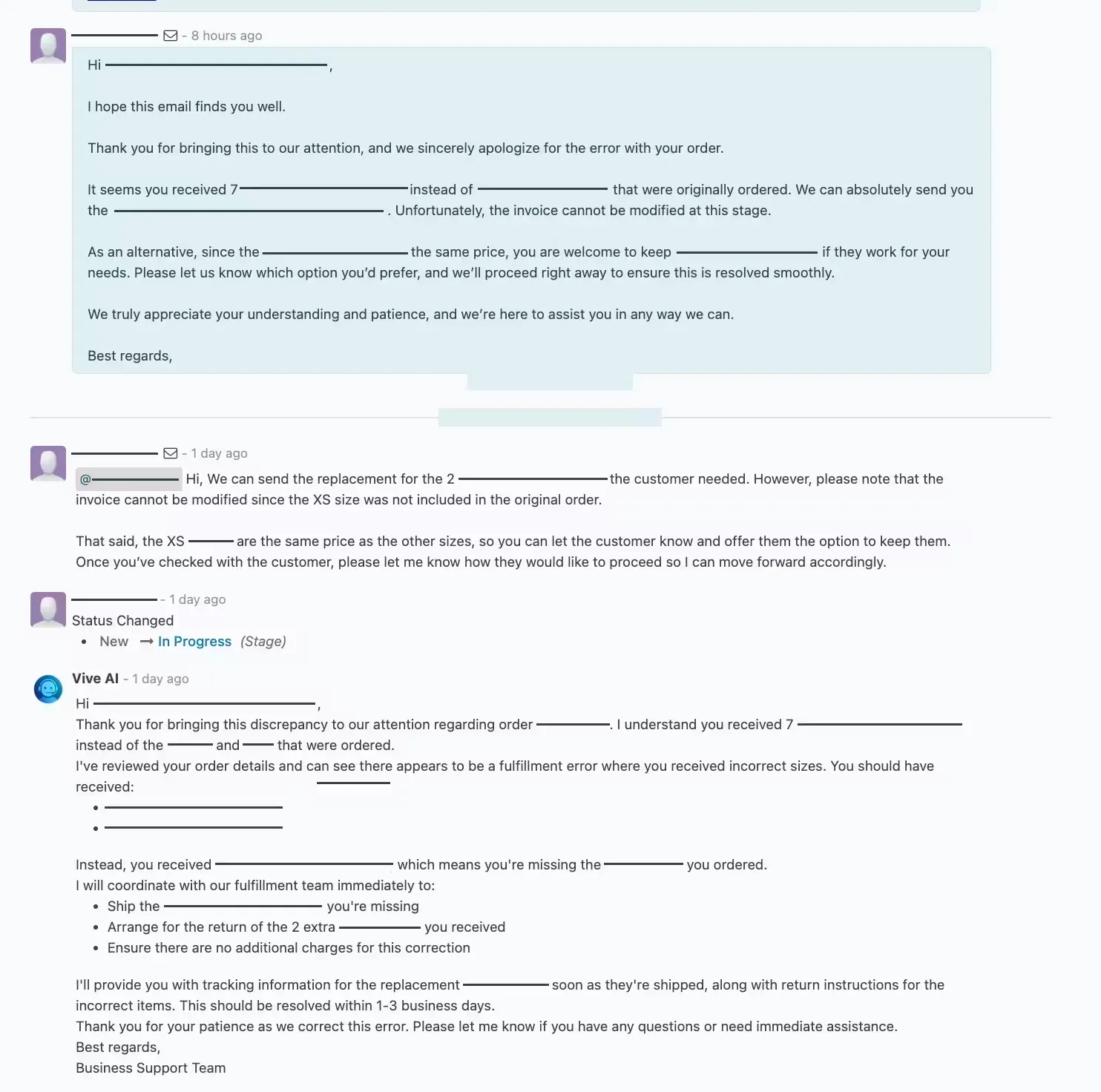
Rung three: approval-gated actions. Then the agent began doing real work in the system of record – creating draft quotations, updating cases – but nothing reaches a customer without a person confirming it. The team opens the draft, verifies it, and sends, or edits first.
Every rung keeps the same guarantees: a human can override any decision, and nothing customer-facing goes out without approval. As confidence in a given workflow proves out, the amount of human involvement it needs narrows – but it’s the team’s call when to let go, not the system’s.
One Case, Start to Finish
Every request follows the same path – intake, understanding, classification and routing, the next best action, human approval, resolution. Here is that path, and what a single order request looks like moving through it.
A request arrives. A B2B customer emails the helpdesk: “Please see attached PO for our next order.” The body says almost nothing; the real content is a purchase order attached as a scanned PDF.
The case is created and classified. The agent opens a case, reads the message and the attachment, classifies it as an order, and sets priority – a routine reorder, not an emergency. The quotation workflow takes over.
The document is parsed. From the PDF the agent extracts the company name, PO number, ship-to address, and every line item with its SKU, quantity, and price – turning a scanned image into structured data.
The account is verified. It looks the customer up in Odoo, reads their payment terms (Net 30), and checks for overdue invoices. The account is clear, so nothing blocks the order. It also reads the internal notes on the customer for any special handling.
History is pulled in. Two line items match catalog SKUs exactly. A third is written loosely – “3-in-1 step-down LSO brace.” The agent runs a semantic match against the product catalog and, to be sure, checks this customer’s previous cases: they’ve ordered that exact variant twice before. High confidence. The match is applied.
A gap is caught. The ship-to address on the PO is missing a suite number. Rather than guess, the agent flags it on the case and drafts a short note asking the customer to confirm – the one thing it genuinely can’t resolve on its own.
The work is prepared, not sent. With everything else confirmed, the agent creates a draft quotation in Odoo – correct customer, terms, address, and matched line items – and posts the link back into the helpdesk ticket, alongside a drafted reply to the customer.
A human approves. A team member opens the draft, sees the quotation is right and the address question is reasonable, and sends. What used to be a multi-step manual chain becomes a quick review.
It’s documented and closed. Every step – the parsed PO, the lookups, the reasoning, the match confidence, the human’s approval – is logged on the case. If anyone asks later why the agent did what it did, the answer is right there.
The Architecture
The technical approach prioritized reliability and observability over speed-to-market.
Deliberate, multi-step processing. Case handling doesn’t need sub-second latency – it needs to be right. The agent gathers context, reasons through the case in steps rather than a single pass, catches conflicts and missing information, and flags low-confidence situations for a human instead of bluffing.
Deep integration with the system of record. The agent reads from and writes to Odoo – customer lookups, payment terms, overdue balances, internal notes, product search, and draft quotation creation. We built the integration to work across Odoo’s interfaces so it keeps running through the platform’s own API migration.
Resilience against real-world failure. Early analysis surfaced requests that got no response at all because of transient API failures. We added retry logic with exponential backoff, so a momentary outage no longer means a dropped case.
Observability as a feature. Every request captures the full trace – the original message, extracted identifiers, the system queries made, the agent’s reasoning, the action it prepared, and any errors. When something fails, we can reproduce exactly what happened. Structured logging and monitoring make problems visible before customers feel them.
How It Keeps Getting Better
A system like this is never finished – it’s tuned.
A feedback loop on every action. The team rates the agent’s output, and that feedback is stored per case. It tells us which request types need work, which scenarios cause confusion, and which the agent already handles well – turning everyday review into a steady improvement signal.
The golden dataset is the foundation everything else stands on. Before tuning a single prompt, we curated a golden dataset – real historical cases paired with the outcome an experienced team member actually produced: the correct quotation for that PO, the right reply, the right next step. This is the most valuable asset in the entire system. The model will be swapped out; the prompts will be rewritten ten times over; the dataset is what endures and compounds. It encodes how Vive’s best people actually make decisions – knowledge that lived in their heads and now lives somewhere the system can be measured against.
Without it, “is the AI good enough?” is an argument. With it, it’s a number. Instead of debating whether the agent feels reliable, we score its output against known-correct answers. On the quotation workflow, we ran the agent against real historical order tickets and compared what it created line-by-line against what the team produced for the same tickets – successful-creation rate, correct SKUs, correct quantities, correct prices, correct addresses.
Regression testing on every change. Each adjustment to a prompt, a workflow, or an underlying model runs against the full golden dataset before it ships. A fix that quietly breaks three other scenarios surfaces immediately, not three weeks later in a customer complaint. The same dataset lets us evaluate a newer model against the current one on Vive’s actual work – not a generic benchmark – before swapping anything in. And it grows: every case the team corrects through the feedback loop becomes another labelled example, so the benchmark sharpens as the system runs.
This is also what makes the automation ladder safe to climb. Each rung – from silent suggestions to approval-gated actions – is earned with evidence, not optimism: the golden dataset is how we prove the agent matches human judgment on a given workflow before we trust it to act there. It’s the same discipline we bring to every AI system we build, and the single biggest reason a project succeeds or stalls – the difference between an agent that demos well and one that holds up in production.
A prompt library the team owns. The logic that drives the agent lives in an editable prompt library, so Vive’s own team can refine tone, rules, and edge-case handling as their process evolves – without waiting on a release.
How We Worked Together
Building AI for customer operations takes more than prompting skill. It takes understanding the business.
Process mapping came before code. We studied how the team actually handled requests – which workflow each request type triggered, which identifiers they looked for, what they pulled from the system, when they made exceptions. The agent mirrors their real decision-making, not a theoretical ideal.
Iterative build with constant validation. A proof of concept first, then the understanding layer, then the action workflows, then automated tests, then background monitoring, then suggestions, then approval-gated actions. Each phase was validated before the next. No big-bang launches.
Honest about the limits. We were direct about what the agent could and couldn’t do. Full autonomy on day one wasn’t realistic – and wasn’t safe. Edge cases would surface that no one had anticipated. We built the staging, the observability, and the feedback loop precisely because that’s how promising technology becomes trusted automation.
Where It Stands
The agent is live, turning incoming requests into resolved cases across Vive’s B2B operations – understanding intent, parsing documents, drafting actions, and acting within the boundaries the team sets. Quotation creation, the single largest category of the support workload, now runs through it end to end.
From here, the same decision logic extends outward – more channels, more case types, more workflows climbing the same automation ladder as confidence grows.
What started as work no one could keep up with by hand has become a system that handles the complete case – from first contact to resolution – with the reliability customer operations actually demand.

