AI Lookalike Company Search for a Marketing Automation Platform
Last updated on December 22, 2025
We build and advise on production AI systems. Bring your questions to a free intro call.
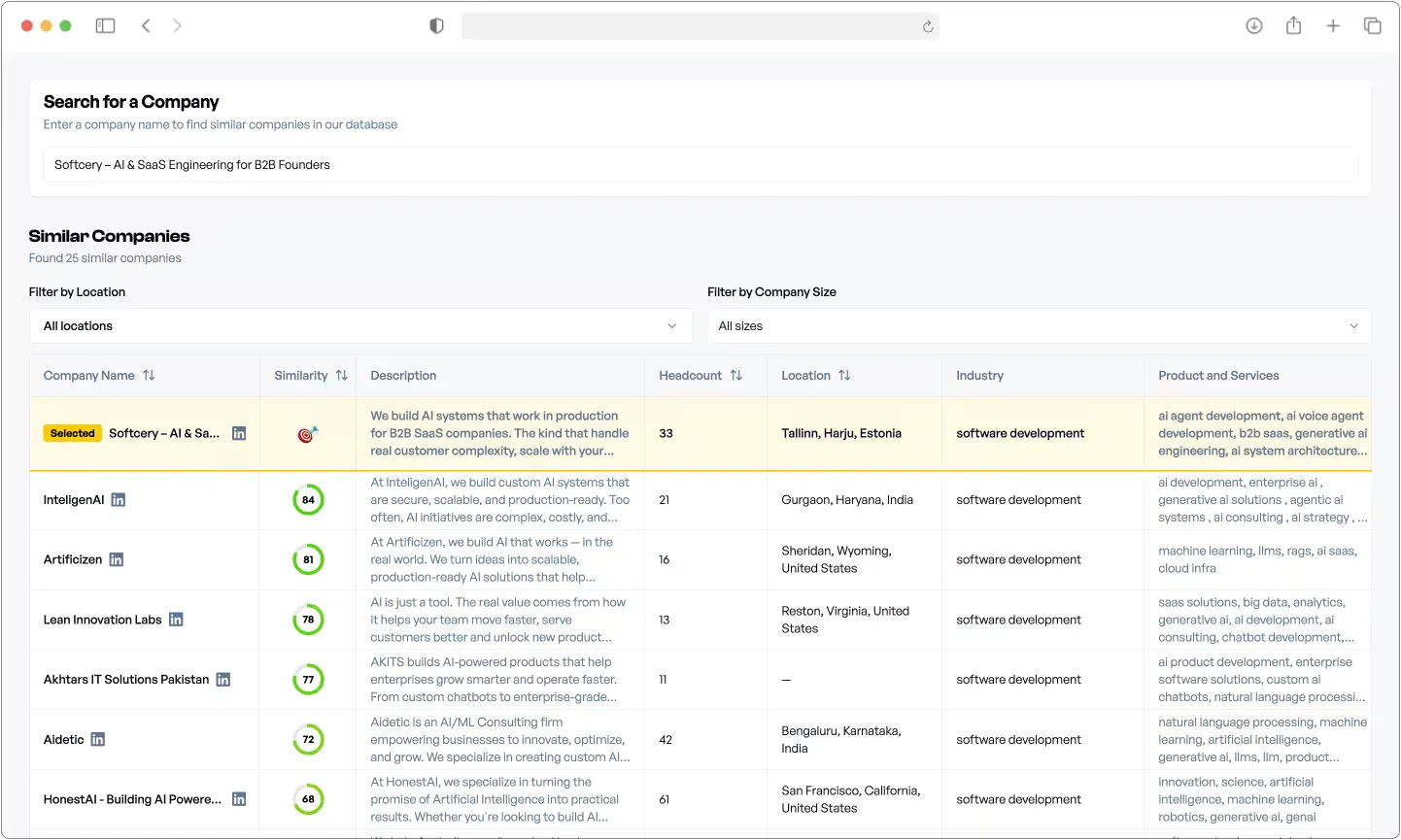
Talk to us“Find me companies like this one.”
Simple request. Impossible for keyword search. A 500-person enterprise consultancy and a 10-person boutique agency both show up under “software development” – but they’re nothing alike. When you’re prospecting at scale, false matches waste time. Missed matches cost deals.
B2B data platforms face this constantly. A data platform approached us with this exact challenge – their sales teams searched across 120,000+ company records, but keyword search kept failing them.
The Problem
Look-alike search sounds simple – users say “find me companies similar to this one” and get accurate results. It isn’t.
Same meaning, different words. Keyword matching finds companies mentioning “AI development” but misses “machine learning consultancies” or “intelligent automation providers.” A search for “AWS deployment solutions” won’t surface “cloud infrastructure services” – even though they’re nearly identical businesses.
Category filters are too rigid. A 500-person enterprise consultancy and a 10-person boutique agency both fall under “software development.” Same category, completely different companies.
Scale makes it worse. Poor matching wastes time on irrelevant results. Good matching surfaces opportunities that keyword search would never find.
The solution required search that grasps meaning, not just text.
The Solution
A hybrid semantic search engine understands similarity across multiple dimensions simultaneously. The system doesn’t just match keywords - it understands what companies actually do, where they operate, and how they describe themselves.
The architecture uses a triple-vector approach. Each company gets encoded into three separate embedding spaces:
- What they offer – services, capabilities, solutions
- Who they are – company description, positioning, identity
- Where they operate – geographic presence and market focus
When a user searches for similar companies, the engine queries all three vector spaces in parallel, then combines results using weighted scoring. Description similarity carries more weight than services alone. Location filters apply minimum thresholds rather than hard cutoffs. The result: nuanced matching that captures how companies are actually similar, not just which keywords they share.
Why Semantic Search Works
Traditional text search operates on exact matching. The query “machine learning consulting” finds documents containing those words. Semantic search operates on meaning. The same query finds companies offering “AI advisory services,” “deep learning solutions,” or “neural network implementation” – because the system understands these concepts are related.
This difference matters enormously at scale. Keyword search returns either too few results (exact matches only) or too many (any document mentioning “machine” or “learning”). Semantic search returns the right results – companies actually similar in meaning, even when they use completely different vocabulary.
Meaning becomes geometry. The embedding model transforms text into high-dimensional vectors where semantic similarity equals geometric proximity. Companies with similar meanings cluster together in vector space, regardless of the specific words they use.
How We Built It
-
Multi-Vector Embedding Architecture – Each record encoded into separate embedding spaces for different attributes, enabling similarity matching across multiple dimensions rather than flattening everything into a single representation
-
Weighted Parallel Search – Queries processed against all vector collections simultaneously, results combined using configurable weights (services 30%, description 70%) to balance different similarity aspects
-
AI-Powered Reranking – Initial vector results refined through a reranking model that applies deeper language understanding, reordering matches by true semantic relevance rather than raw vector distance
-
Smart Bucketing for Filters – Numeric attributes like company size use intelligent bucketing (1-10, 11-50, 51-200) rather than exact matching, finding records in similar ranges without arbitrary cutoffs
-
Parallel Embedding Generation – Batch processing with concurrent API calls enables efficient indexing of large datasets by embedding multiple text fields simultaneously
Technical Approach
The system combines vector embeddings for semantic understanding with AI reranking for precision. This hybrid approach outperforms either technique alone.
Why Multi-Vector
Each record gets embedded into multiple vector spaces rather than one. This separation preserves distinct semantic dimensions that would blur together in a single embedding. When you combine “enterprise cloud consulting firm in Germany” into one vector, you lose the ability to weight geography differently than services.
Single-vector approaches compress all attributes into one representation, making it impossible to weight dimensions differently at search time. Multi-vector search lets you find companies that match services closely but operate in different regions – or companies in the same region with different services. The search becomes configurable based on what matters for each query.
The tradeoff. Multiple collections mean multiple embeddings to generate, store, and query. Parallel processing and efficient batching make this manageable, but the architecture requires more infrastructure than simple single-vector search.
The Search Pipeline
The search pipeline implements a two-stage scoring system that first combines multiple vector similarities, then applies AI reranking, and finally blends these scores for optimal results.
Stage one: Parallel vector retrieval. The system queries all three vector collections simultaneously – services, description, location. Each collection returns candidates with similarity scores, combined using tunable weights. Description carries more weight than services alone, with location acting as a filter rather than a ranking signal.
Stage two: AI reranking. Top candidates from stage one pass through a reranking model that applies deeper language understanding. The reranker evaluates query-document pairs more thoroughly than vector distance alone, catching semantic relevance that embedding similarity might miss.
Score blending. Final ranking blends vector similarity scores with rerank scores using configurable weights. This allows tuning the balance between fast vector retrieval (good at finding candidates) and expensive reranking (good at precision ordering).
The Result
The platform’s look-alike search now finds companies that are semantically similar – not just keyword matches. Users describe what they’re looking for or provide an example company, and the system returns relevant matches ranked by actual similarity. No more missing opportunities because a prospect used different words to describe the same thing.
The multi-vector approach captures nuance that single-vector systems miss. A company might have similar services but different positioning, or similar positioning but different geographic focus. Separate embedding spaces let the system weight these dimensions appropriately rather than averaging them into a single score. Users find companies that match on the dimensions that matter most to them.
Search performance stays fast regardless of dataset size. Vector similarity search operates in sub-linear time – doubling the dataset doesn’t double the search time. Users get instant results whether searching across thousands or millions of records.
The reranking layer handles edge cases where pure vector distance doesn’t capture true relevance. Initial retrieval casts a wide net; reranking applies sophisticated language understanding to surface the best matches first. The combination delivers both speed and precision.