AI Marketing Consultant: Productizing Agency Expertise
Last updated on January 6, 2026
We build and advise on production AI systems. Bring your questions to a free intro call.
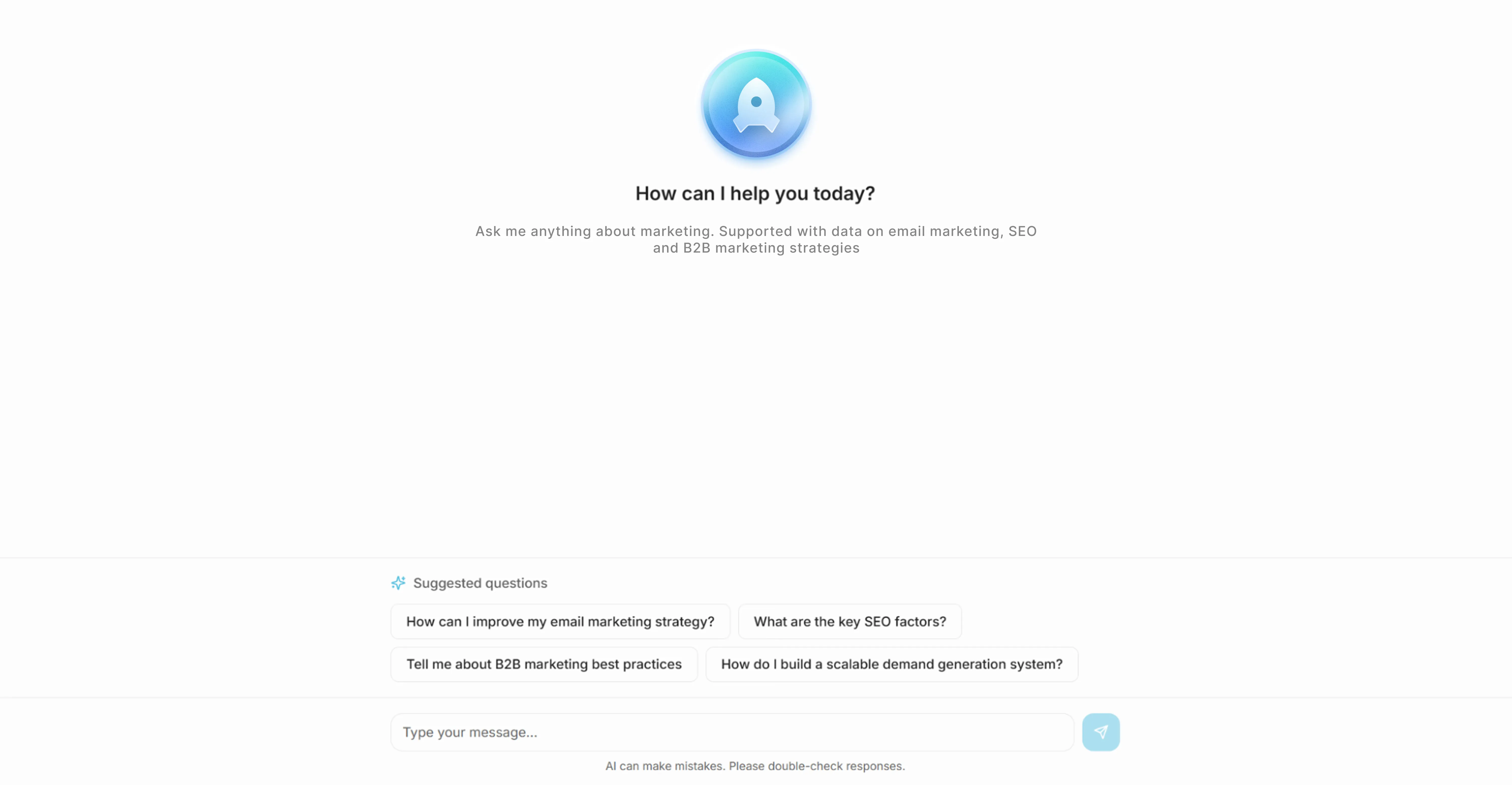
Talk to us“How do I improve my email open rates?”
The answer exists – buried across blog posts, guides, and documentation. Finding and synthesizing it takes 30 minutes. The person asking needs it in 30 seconds.
A digital marketing agency specializing in SEO, PPC, email marketing, and conversion rate optimization had built extensive expertise across hundreds of blog articles, guides, and resources covering complex marketing strategies. The knowledge existed. Accessing it required manual excavation through long-form content that clients wouldn’t do.
The Problem
The agency faced the challenge of making their extensive marketing knowledge accessible and actionable for clients who needed expert guidance on demand. Three core problems emerged:
Clients can’t find answers. The knowledge exists across hundreds of blog posts. But clients asking “How do I improve my email open rates?” won’t read through ten 3,000-word articles to find it. They need guidance now.
Consultants become the bottleneck. Every question routes to human experts. Email segmentation, meta descriptions, internal linking – consultants answer the same fundamental questions repeatedly. As client volume grows, this doesn’t scale.
Static content requires manual synthesis. A question about email deliverability might need insights from four different articles. Traditional search returns links, not answers. Clients need synthesis, not a reading list.
The Solution
We built an AI-powered marketing advisor that transforms the agency’s knowledge base into an interactive conversational assistant, delivering expert guidance in 30-60 seconds with citations to source materials.
The system works in three phases:
Knowledge Indexing. Articles are automatically processed and split into meaningful sections that preserve context. Each section gets indexed for semantic search – finding content by meaning, not just keywords.
Smart Retrieval. When a client asks a question, the system finds the most relevant content across the entire knowledge base. The agent can search multiple times, refining its understanding before responding.
Expert Response. Claude analyzes the retrieved content, connects insights from multiple sources, and generates a comprehensive answer. Responses stream naturally, and every claim links back to source articles.
How We Built It
-
Automated ETL Pipeline – Content flows through filtering, scraping, parsing, chunking, embedding, and indexing – fully automated, no manual handling
-
Semantic Chunking – Documents split by meaning, not arbitrary token counts. Sections stay coherent, tables stay intact, context preserved
-
Vector Search – Sub-second similarity queries across thousands of content chunks using production-grade indexing
-
Multi-Pass Retrieval – The agent searches iteratively, refining understanding before responding – not limited to a single query
-
Streaming UX – Real-time response delivery with natural reading rhythm
Technical Approach
The architecture demonstrates production-quality engineering across data pipeline, retrieval infrastructure, and user experience.
Modular Architecture. Clean separation of concerns with single-responsibility components. Content extraction, embedding generation, and reasoning each handled independently. Providers can be swapped – switching embedding models or LLMs requires configuration changes, not code rewrites.
Knowledge Pipeline. The system filters noise – navigation elements, newsletter prompts, table of contents links – that would pollute the knowledge base. Metadata flows through the entire pipeline for traceability and debugging: source URL, article title, section name.
Extended Thinking. Claude’s thinking budget enables genuine synthesis rather than simple retrieval. The model reflects on retrieved information, identifies gaps, and reasons about which insights are most relevant to the specific question. Responses feel like expert consultation, not keyword matching.
Citation Integrity. Every claim links to source articles – citations are programmatically verified, not generated by the LLM. Users can trust and verify any recommendation.
Performance Numbers. Vector search returns results in under 100ms across thousands of content chunks. Streaming responses with natural pacing prevent wall-of-text overload – users read as the response generates.
Cost Advantages. Embeddings are generated once per article and reused for unlimited queries – full knowledge base indexes for approximately $15. Each query costs $0.15-0.20, a fraction of consultant time. At scale, 1,000 queries/month runs under $200. No per-seat licensing, no infrastructure overhead.
The Result
Clients receive expert marketing guidance instantly instead of waiting for consultant availability or spending hours browsing blog content.
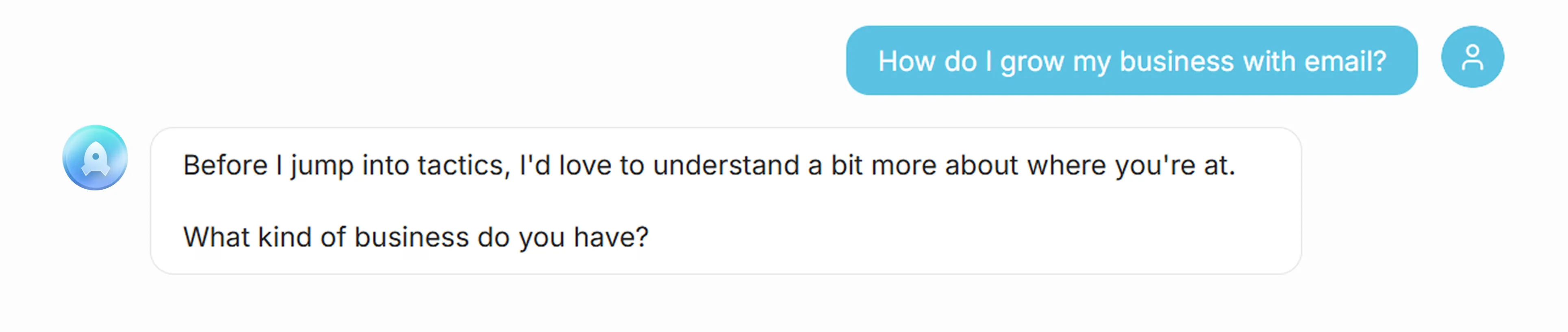
24/7 expert guidance. Questions answered in under a minute – comprehensive, multi-source responses with citations. No waiting for consultant availability. No browsing through articles. Every response maintains consistency with the agency’s methodology, ensuring clients receive advice aligned with proven frameworks.
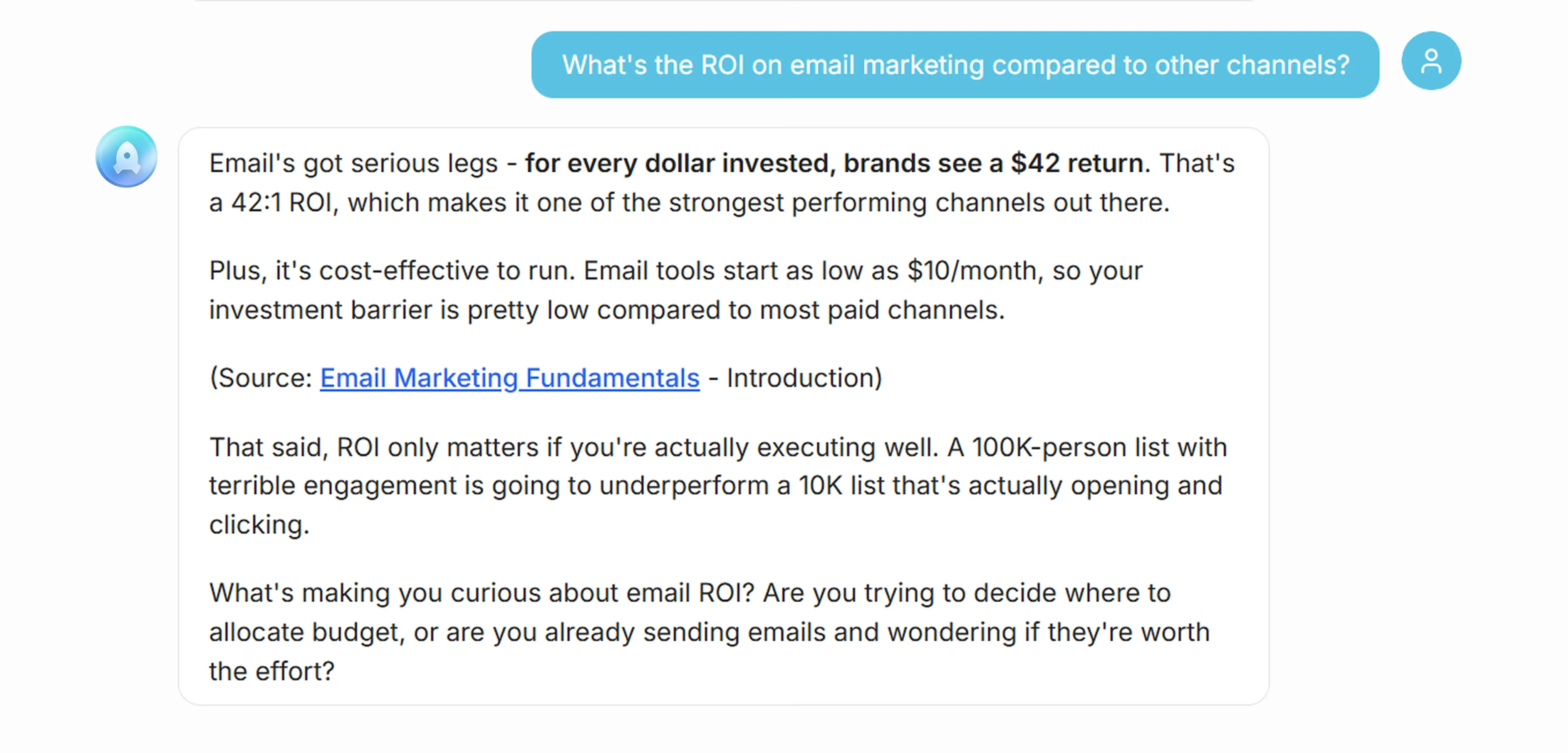
Knowledge unlocked. Expertise buried in 100+ articles is now accessible through conversation. Clients get synthesized answers they’d never find through traditional search. A question about email deliverability pulls insights from articles on sender reputation, list hygiene, and authentication – information that would require reading four separate posts.
Consultants freed. Repetitive questions handled automatically. Consultants focus on strategy and high-value relationships instead of answering the same questions repeatedly. The foundation supports expansion to additional domains by simply ingesting more content.
| Metric | Impact |
|---|---|
| Response Time | 30-60 seconds with streaming |
| Knowledge Coverage | 100+ articles fully indexed |
| Search Time | Hours of browsing → 1 question to AI agent |
Real-world example. A client asks: “What’s the best way to improve my email open rates?”
The agent searches across the knowledge base, finds relevant content from multiple articles, and synthesizes a response:
“Personalized subject lines (using recipient name or company) can increase open rates 15-20%. Test send times between 10am-11am and 2pm-3pm in the recipient’s timezone. Segment your list by engagement history – send re-engagement campaigns to inactive subscribers separately. Maintain sender reputation by keeping bounce rates below 2%.”
Four source articles cited. One question. 30 seconds.

